
Target Audience: The target audience for this article’s introduction to Exploratory Data Analysis (EDA) would-be students and beginners in the field of data science, machine learning, and data analytics, as well as professionals working in industries that involve data-driven decision-making, such as finance, healthcare, retail, and social media. Researchers and analysts who need to gain insights from complex datasets would also find this guide valuable.
Value Proposition: This article on Exploratory Data Analysis provides immense value to the target audience by thoroughly understanding the fundamental concepts, techniques, and tools used in EDA. It demonstrates the importance of EDA as a crucial step in the data analysis and machine learning pipeline and equips readers with practical skills to effectively explore, visualize, clean, and prepare data for further analysis and modeling. The guide also showcases real-world case studies and examples across various domains to illustrate the application of EDA, covers advanced EDA techniques, and addresses common challenges, preparing readers for more complex data analysis tasks.
Key Takeaways: By the end of this comprehensive article, readers will be able to define and understand the historical background, importance, and key concepts of Exploratory Data Analysis; leverage a wide range of Python libraries and R packages to perform EDA, including data visualization, descriptive statistics, and data cleaning; apply a structured, step-by-step approach to conduct EDA, from data collection to interpretation of results; gain insights into data distribution, identify outliers, and understand the relationships between variables; prepare data for machine learning model building by performing feature selection and engineering; recognize and address common challenges faced during EDA, such as handling large datasets and noisy data; and appreciate the role of EDA in the broader context of data science and machine learning projects.
EDA: Definition, Importance, and Introduction Overview
Exploratory Data Analysis (EDA) is a critical process in the data analysis workflow, where data scientists and analysts use statistical graphics and other data visualization methods to understand the data’s structure, identify patterns, detect anomalies, test hypotheses, and check assumptions.
Importance: EDA serves as a foundational step in data analysis, allowing practitioners to:
- Gain initial insights into data before applying more complex statistical models.
- Identify errors and missing values in the dataset.
- Understand the underlying relationships between variables.
- Formulate hypotheses for further analysis.
Historical Background
1970s:
- 1977: John Tukey publishes “Exploratory Data Analysis,” which introduces the EDA framework. Tukey’s work emphasizes the importance of exploring data visually and statistically before applying formal modeling techniques. This publication marks the beginning of EDA as a distinct approach in data analysis.
1980s:
- The 1980s see an increased recognition of EDA in academic and applied research fields. Tukey’s methods are further developed and popularized, leading to the creation of new graphical tools and techniques for data exploration.
1983:
- The introduction of the software package S, which later evolved into R, provides powerful tools for data manipulation and visualization, aiding the practice of EDA. The development of the S language at Bell Labs by John Chambers and colleagues helps embed EDA techniques into the daily practice of statisticians.
1990s:
- EDA techniques become more integrated into statistical software packages, making them more accessible to a wider audience. The growth of personal computing allows for more extensive use of graphical methods in data analysis.
1995:
- The release of the R programming language, an open-source implementation of the S language, democratizes access to EDA tools. R’s extensive library of packages facilitates sophisticated data visualization and exploration, making EDA more prevalent in both academia and industry.
2000s:
- The rise of data science as a discipline sees EDA become a fundamental component of data analysis workflows. With the advent of big data, EDA techniques are adapted to handle larger and more complex datasets.
2001:
- The publication of “The Grammar of Graphics” by Leland Wilkinson introduces a systematic approach to data visualization, influencing the development of the ggplot2 package in R. ggplot2 becomes a cornerstone for EDA, enabling the creation of complex and customizable plots.
2010s:
- EDA becomes more integral to machine learning and predictive analytics workflows. Data visualization libraries such as Matplotlib, Seaborn, Plotly in Python, and ggplot2 in R, provide powerful tools for EDA.
2015:
- The development of interactive visualization tools like Tableau and Power BI further enhances EDA capabilities, allowing users to interact with data in real time and gain insights more quickly.
2020s:
- Advances in artificial intelligence and machine learning lead to the integration of automated EDA tools that help analysts quickly uncover patterns and insights. Open-source platforms and cloud computing make these tools more accessible.
2024:
- EDA continues to evolve with the integration of augmented analytics, where AI-driven insights and recommendations augment human analysis. This fusion enhances the ability to explore data efficiently and effectively, making EDA a vital skill for modern data professionals.
Throughout these decades, EDA has remained a crucial step in understanding data, enabling analysts to make informed decisions and build robust models. The continuous development of new tools and techniques ensures that EDA adapts to the ever-changing landscape of data analysis.
Concepts:
1. Data Visualization: Visualization is a powerful tool in EDA, enabling the easy identification of trends, patterns, and outliers. Common visualization techniques include:
- Histograms: Used to understand the distribution of a single variable.
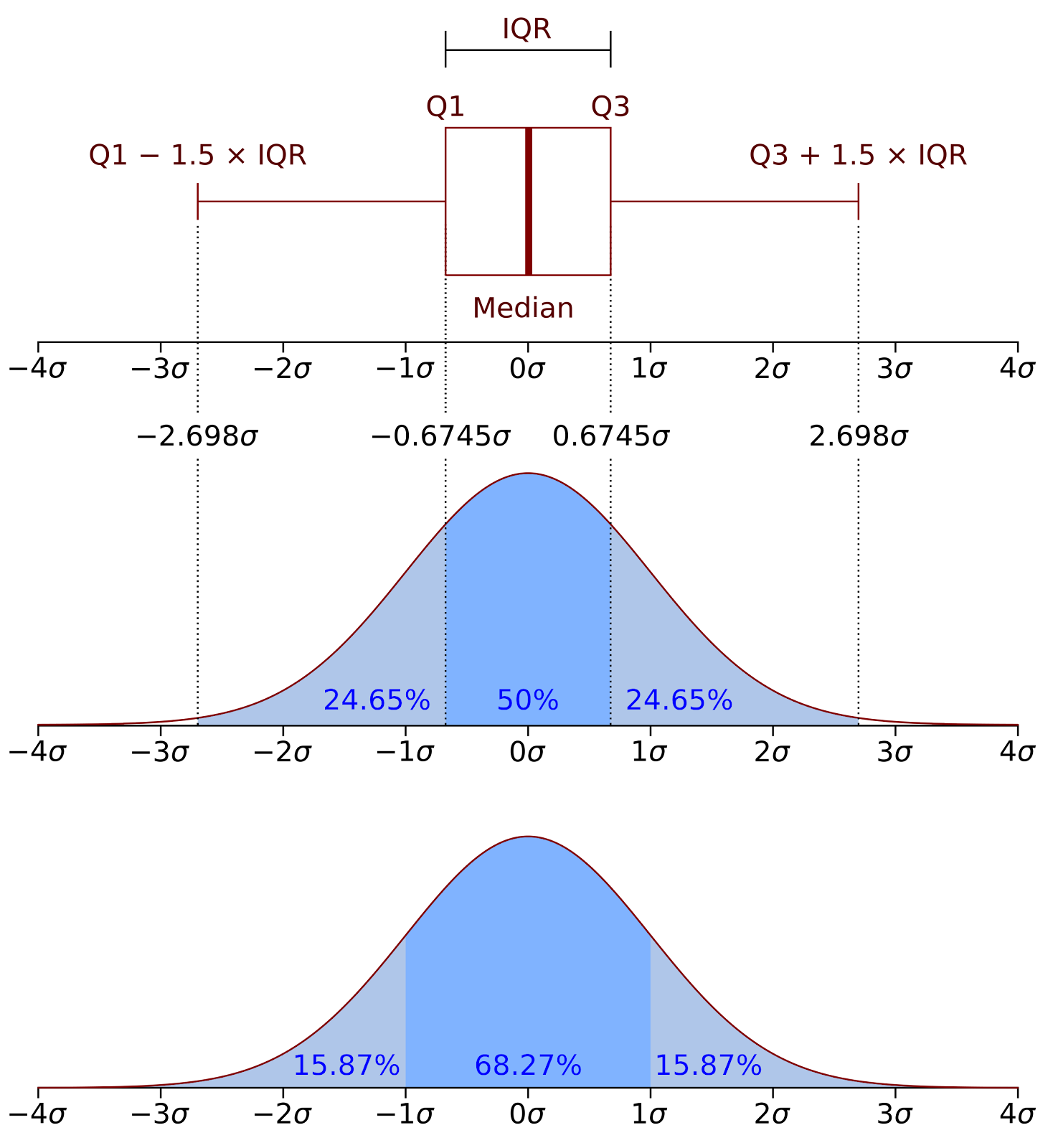
- Box Plots: Useful for identifying the spread and skewness of data and detecting outliers.
Example: A box plot comparing the distribution of test scores across different classes. - Scatter Plots: Ideal for exploring relationships between two continuous variables.
2. Summary Statistics: Summary statistics provide a quick overview of the data and include measures such as:
- Mean: The average value of the data.
- Median: The middle value when the data is ordered.
- Mode: The most frequently occurring value.
- Standard Deviation: A measure of the dispersion or spread of the data.
3. Data Cleaning: EDA often involves data cleaning, which includes handling missing values, correcting errors, and removing duplicates.
- Example: Replacing missing values in a dataset with the mean or median value.
4. Identifying Patterns and Relationships: Through visualizations and summary statistics, EDA helps identify correlations and potential causal relationships between variables.
- Example: Using a correlation matrix to identify strongly correlated variables.
5. Hypothesis Testing: EDA allows for the generation of hypotheses that can be tested with formal statistical methods.
- Example: Observing a pattern in the data that suggests a potential cause-effect relationship, which can then be tested using regression analysis.
Practical Example: EDA on a Student Performance Dataset
Let’s walk through a practical example using a student performance dataset.
Step 1: Load the Data
Python code
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Load the dataset
data = pd.read_csv(‘student_performance.csv’)
Step 2: Summary Statistics
Python code
# Summary statistics
print(data.describe())
Step 3: Data Visualization
Python code
# Histogram of exam scores
sns.histplot(data[‘exam_score’], kde=True)
plt.title(‘Distribution of Exam Scores’)
plt.show()
# Scatter plot of study hours vs. exam scores
sns.scatterplot(x=’study_hours’, y=’exam_score’, data=data)
plt.title(‘Study Hours vs. Exam Scores’)
plt.show()
Step 4: Identify Relationships
Python code
# Correlation matrix
correlation_matrix = data.corr()
sns.heatmap(correlation_matrix, annot=True, cmap=’coolwarm’)
plt.title(‘Correlation Matrix’)
plt.show()
This example illustrates how EDA provides valuable insights into data, helping to inform the next steps in the data analysis process.
Exploratory Data Analysis is an indispensable step in any data science project. By employing a combination of visual and statistical techniques, EDA allows us to uncover the underlying structure of data, identify key patterns, and prepare for more sophisticated analyses. Mastering EDA equips students with the tools to approach data with curiosity and rigor, ultimately leading to more robust and insightful findings.
Key Concepts in EDA
Exploratory Data Analysis (EDA) is an approach to analyzing data sets to summarize their main characteristics, often with visual methods. EDA is a critical step in the data analysis process, allowing us to uncover patterns, spot anomalies, frame hypotheses, and check assumptions through visual and statistical techniques.
Descriptive Statistics
Descriptive statistics provide a summary of the main features of a data set, giving a simple but powerful overview of the data. Key measures include:
- Mean (Average): The sum of all data points divided by the number of points.
- Median: The middle value when data points are ordered.
- Mode: The most frequently occurring value.
- Standard Deviation: A measure of the amount of variation or dispersion in a set of values.
- Variance: The average of the squared differences from the mean.
- Range: The difference between the highest and lowest values.
Example: Consider a dataset of test scores: [70, 80, 85, 90, 95].
- Mean: (70 + 80 + 85 + 90 + 95) / 5 = 84
- Median: 85
- Mode: No mode (all values are unique)
- Standard Deviation: √[( (70-84)² + (80-84)² + (85-84)² + (90-84)² + (95-84)² ) / 5] = 8.6
- Range: 95 – 70 = 25
Data Visualization
Visualizing data helps to see patterns, trends, and outliers in the dataset. Common visualization techniques include:
- Histograms: Show the distribution of a dataset.
- Box Plots: Summarize data using a five-number summary (minimum, first quartile, median, third quartile, and maximum).
- Scatter Plots: Show relationships between two variables.
- Bar Charts: Compare different categories of data.
- Line Graphs: Display data points over time.
Example: A histogram of the test scores [70, 80, 85, 90, 95] will show the frequency distribution of scores.
Data Cleaning and Preparation
Data cleaning involves fixing or removing incorrect, corrupted, or incomplete data. Steps include:
- Handling Missing Values: Techniques such as imputation (filling in missing values) or removing rows/columns with missing values.
- Removing Duplicates: Ensuring there are no repeated data entries.
- Correcting Errors: Fixing typos, incorrect formats, and inconsistencies.
- Standardizing Data: Ensuring consistent units and formats.
Example: For a dataset containing names, ages, and test scores:
- Missing pages might be filled with the mean age.
- Duplicate rows with identical entries will be removed.
Detecting Outliers
Outliers are data points that are significantly different from others in the dataset. They can be identified using:
- Box Plots: Outliers appear as individual points outside the whiskers.
- Z-scores: Data points with a Z-score greater than 3 or less than -3 are often considered outliers.
- IQR (Interquartile Range) Method: Points that fall below Q1 – 1.5IQR or above Q3 + 1.5IQR are outliers.
Example: In the test scores dataset [70, 80, 85, 90, 150], 150 is an outlier.
Understanding Data Distribution
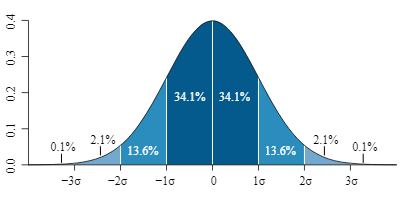
Understanding the distribution of data helps in identifying the shape and spread of data, which is crucial for selecting appropriate statistical methods. Common distributions include:
- Normal Distribution: Data is symmetrically distributed around the mean.
- Skewed Distribution: Data asymmetrically distributed, with a tail on one side.
- Bimodal Distribution: Data with two distinct peaks.
Example: A normal distribution of test scores with a mean of 85 and a standard deviation of 8.6.
By understanding these key concepts in EDA, students can gain practical insights and develop a strong foundation for more advanced data analysis techniques.
EDA Tools and Libraries for Effective Data Analysis
Exploratory Data Analysis (EDA) is a crucial step in the data analysis process. It helps in understanding the data’s underlying structure, spotting anomalies, and identifying patterns. Various tools and libraries facilitate this process, each with its unique strengths. Below, we’ll explore some of the most popular tools and libraries used for EDA in Python and R, along with software tools like Excel, Tableau, and Power BI.
Python Libraries
1. Pandas
Description: Pandas is a powerful data manipulation library. It provides data structures like DataFrames that make it easy to manipulate and analyze data.
Example:
Python code
import pandas as pd
# Load dataset
df = pd.read_csv(‘data.csv’)
# Basic operations
print(df.head()) # Display first 5 rows
print(df.describe()) # Summary statistics
print(df.info()) # Data types and non-null values
2. NumPy
Description: NumPy is the foundation of scientific computing in Python. It provides support for large multi-dimensional arrays and matrices.
Example:
Python code
import numpy as np
# Create a NumPy array
data = np.array([1, 2, 3, 4, 5])
# Basic operations
print(np.mean(data)) # Mean of the array
print(np.std(data)) # Standard deviation of the array
3. Matplotlib
Description: Matplotlib is a plotting library for creating static, animated, and interactive visualizations.
Example:
Python code
import matplotlib.pyplot as plt
# Plotting a simple line chart
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.title(‘Line Chart Example’)
plt.xlabel(‘X-axis’)
plt.ylabel(‘Y-axis’)
plt.show()
4. Seaborn
Description: Seaborn is built on top of Matplotlib and provides a high-level interface for drawing attractive statistical graphics.
Example:
Python code
import seaborn as sns
import pandas as pd
# Load dataset
df = sns.load_dataset(‘tips’)
# Creating a boxplot
sns.boxplot(x=’day’, y=’total_bill’, data=df)
plt.title(‘Boxplot of Total Bill by Day’)
plt.show()
5. Plotly
Description: Plotly is an interactive graphing library. It makes it easy to create interactive plots that can be embedded in web applications.
Example:
Python code
import plotly.express as px
# Load dataset
df = px.data.iris()
# Creating a scatter plot
fig = px.scatter(df, x=’sepal_width’, y=’sepal_length’, color=’species’)
fig.show()
R Packages
1. dplyr
Description: dplyr is a grammar of data manipulation, providing a consistent set of verbs to help solve the most common data manipulation challenges.
Example:
r code
library(dplyr)
# Load dataset
data <- mtcars
# Basic operations
summary <- data %>%
group_by(cyl) %>%
summarise(avg_mpg = mean(mpg))
print(summary)
2. ggplot2
Description: ggplot2 is a system for declaratively creating graphics, based on The Grammar of Graphics.
Example:
r code
library(ggplot2)
# Load dataset
data <- mtcars
# Creating a scatter plot
ggplot(data, aes(x=wt, y=mpg)) +
geom_point() +
ggtitle(‘Scatter Plot of MPG vs Weight’) +
xlab(‘Weight’) +
ylab(‘MPG’)

3. tidyr
Description: tidyr helps you create tidy data, which means that the dataset is in a consistent format for analysis.
Example:
r code
library(tidyr)
# Create a dataset
data <- data.frame(
year = c(2010, 2010, 2011, 2011),
key = c(‘A’, ‘B’, ‘A’, ‘B’),
value = c(1, 2, 3, 4)
)
# Spread the data into a wide format
wide_data <- spread(data, key, value)
print(wide_data)
Software Tools
- Excel
- Description: Excel is a spreadsheet tool widely used for data analysis and visualization.
- Example: Use Excel’s built-in functions and chart tools to analyze data. For instance, you can use pivot tables to summarize data and create bar charts or line graphs to visualize trends.
- Tableau
- Description: Tableau is a powerful data visualization tool that helps in creating interactive and shareable dashboards.
- Example: Import a dataset into Tableau and create a dashboard with various charts, such as scatter plots and heatmaps, to analyze data trends and patterns interactively.
- Power BI
- Description: Power BI is a business analytics tool that provides interactive visualizations and business intelligence capabilities.
- Example: Use Power BI to connect to multiple data sources, transform data, and create interactive reports and dashboards. You can use built-in visuals like bar charts, pie charts, and maps to explore and present your data insights.
By leveraging these tools and libraries, students can perform comprehensive EDA to uncover insights from their data, leading to more informed decision-making and better analytical outcomes.
EDA Analysis: Key Steps in Exploratory Data Analysis
Exploratory Data Analysis (EDA) is a crucial step in the data analysis process. It involves summarizing the main characteristics of a dataset, often using visual methods. EDA helps in understanding the data, detecting anomalies, checking assumptions, and identifying patterns before proceeding with more sophisticated modeling. Here are the essential steps in EDA:
1. Data Collection
Definition: Data collection is the process of gathering information from various sources to be used for analysis. This can involve collecting data through surveys, experiments, sensors, web scraping, APIs, or accessing existing databases.
Example: Suppose you want to analyze customer satisfaction for an e-commerce platform. You might collect data through customer feedback forms, reviews, transaction records, and customer support interactions.
2. Data Cleaning
Definition: Data cleaning involves preparing the data for analysis by removing or correcting inaccurate records, handling missing values, and correcting inconsistencies.
Key Tasks:
- Removing duplicates: Eliminating duplicate records that can skew analysis results.
- Handling missing values: Replacing, imputing, or dropping missing data.
- Correcting errors: Fixing data entry mistakes and standardizing formats.
Example: In the customer satisfaction dataset, you might find missing customer ages or incorrectly formatted email addresses that need correction.
3. Data Transformation
Definition: Data transformation involves converting data into a suitable format for analysis. This can include normalization, scaling, encoding categorical variables, and creating new features.
Key Tasks:
- Normalization: Adjusting values measured on different scales to a common scale.
- Encoding: Converting categorical data into numerical form.
- Feature engineering: Creating new features based on existing data to enhance model performance.
Example: For the e-commerce dataset, transforming customer ages into age groups (e.g., 18-25, 26-35) and encoding the satisfaction levels (e.g., “Very Satisfied” to 5, “Dissatisfied” to 1).
4. Data Visualization
Definition: Data visualization is the graphical representation of data to understand patterns, trends, and insights effectively.
Key Techniques:
- Histograms: For understanding the distribution of a single variable.
- Scatter plots: For identifying relationships between two variables.
- Box plots: For visualizing the spread and identifying outliers.
- Heatmaps: For showing the intensity of data points.
Example: Using a scatter plot to visualize the relationship between customer age and satisfaction level, or a histogram to see the distribution of purchase amounts.
5. Interpretation of Results
Definition: Interpretation of results involves concluding the visualizations and statistical analysis. It helps in understanding the underlying patterns and relationships within the data.
Key Considerations:
- Identifying trends: Noticing upward or downward trends in the data.
- Detecting patterns: Observing recurring patterns or cycles.
- Highlighting anomalies: Recognizing outliers or unusual observations.
Example: From the visualizations, you might find that younger customers are generally more satisfied, or that there is a seasonal trend in purchase amounts.
EDA is a foundational step in the data analysis process, providing essential insights and guiding further analysis. By collecting, cleaning, transforming, visualizing data, and interpreting results, you can uncover meaningful patterns and make informed decisions. This process not only prepares your data for advanced modeling but also ensures that you understand the context and nuances of the dataset you are working with.
Practical Insight
For students, practicing EDA with real-world datasets is invaluable. Use tools like Python with libraries such as Pandas, Matplotlib, and Seaborn to perform EDA. By doing so, you will gain hands-on experience and develop a deep understanding of your data, which is crucial for any data-driven project.
Example Code (Python):
Python code
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load dataset
data = pd.read_csv(‘ecommerce_data.csv’)
# Data Cleaning
data.drop_duplicates(inplace=True)
data.fillna(method=’ffill’, inplace=True)
# Data Transformation
data[‘Age Group’] = pd.cut(data[‘Age’], bins=[18, 25, 35, 45, 55, 65, 75])
data[‘Satisfaction Level’] = data[‘Satisfaction’].map({‘Very Satisfied’: 5, ‘Satisfied’: 4, ‘Neutral’: 3, ‘Dissatisfied’: 2, ‘Very Dissatisfied’: 1})
# Data Visualization
plt.figure(figsize=(10, 6))
sns.histplot(data[‘Purchase Amount’], kde=True)
plt.title(‘Distribution of Purchase Amount’)
plt.xlabel(‘Purchase Amount’)
plt.ylabel(‘Frequency’)
plt.show()
# Interpretation of Results
# Scatter plot to visualize the relationship between Age and Satisfaction Level
plt.figure(figsize=(10, 6))
sns.scatterplot(x=’Age’, y=’Satisfaction Level’, data=data)
plt.title(‘Age vs. Satisfaction Level’)
plt.xlabel(‘Age’)
plt.ylabel(‘Satisfaction Level’)
plt.show()
By following these steps, you’ll be well on your way to mastering EDA and making the most of your data analysis projects.
Descriptive Statistics in EDA
Exploratory Data Analysis (EDA) is a crucial step in the data analysis process that helps us understand the underlying structure of our data. Descriptive statistics play a significant role in EDA, providing a summary of the main characteristics of a dataset. This section covers key concepts of descriptive statistics, including measures of central tendency, measures of dispersion, skewness, and kurtosis.
Measures of Central Tendency
1. Mean: The mean is the average of all the data points in a dataset. It is calculated by summing up all the values and dividing by the number of values.
Formula: Mean(xˉ)=∑i=1nxin\text{Mean} (\bar{x}) = \frac{\sum_{i=1}^{n} x_i}{n}Mean(xˉ)=n∑i=1nxi
Example: Consider a dataset of exam scores: 70, 80, 90, 100, and 110. Mean=70+80+90+100+1105=90\text{Mean} = \frac{70 + 80 + 90 + 100 + 110}{5} = 90Mean=570+80+90+100+110=90
2. Median: The median is the middle value when the data points are arranged in ascending order. If the number of data points is even, the median is the average of the two middle values.
Example: For the dataset 70, 80, 90, 100, and 110, the median is 90.
For the datasets 70, 80, 90, and 100, the median is 80+902=85\frac{80 + 90}{2} = 85280+90=85.
3. Mode: The mode is the value that appears most frequently in the dataset. A dataset can have one mode, more than one mode, or no mode at all.
Example: In the datasets 70, 80, 80, 90, and 100, the mode is 80.
Measures of Dispersion
1. Range: The range is the difference between the maximum and minimum values in the dataset.
Formula: Range=Max−Min\text{Range} = \text{Max} – \text{Min}Range=Max−Min
Example: For the dataset 70, 80, 90, 100, and 110, the range is 110−70=40110 – 70 = 40110−70=40.
2. Variance: Variance measures the average squared deviation of each data point from the mean. It gives an idea of how spread out the data points are.
Formula: Variance(σ2)=∑i=1n(xi−xˉ)2n\text{Variance} (\sigma^2) = \frac{\sum_{i=1}^{n} (x_i – \bar{x})^2}{n}Variance(σ2)=n∑i=1n(xi−xˉ)2
Example: For the dataset 70, 80, 90, 100, and 110, the mean is 90.
Variance=(70−90)2+(80−90)2+(90−90)2+(100−90)2+(110−90)25=400+100+0+100+4005=200\text{Variance} = \frac{(70-90)^2 + (80-90)^2 + (90-90)^2 + (100-90)^2 + (110-90)^2}{5} = \frac{400 + 100 + 0 + 100 + 400}{5} = 200Variance=5(70−90)2+(80−90)2+(90−90)2+(100−90)2+(110−90)2=5400+100+0+100+400=200
3. Standard Deviation: The standard deviation is the square root of the variance, providing a measure of dispersion in the same units as the data.
Formula: Standard Deviation(σ)=Variance\text{Standard Deviation} (\sigma) = \sqrt{\text{Variance}}Standard Deviation(σ)=Variance
Example: Using the variance calculated above (200), the standard deviation is 200≈14.14\sqrt{200} \approx 14.14200≈14.14.

Skewness and Kurtosis
1. Skewness: Skewness measures the asymmetry of the data distribution. A dataset can be positively skewed (right-skewed), negatively skewed (left-skewed), or symmetric.
- Positive Skewness: The right tail is longer or fatter than the left tail.
- Negative Skewness: The left tail is longer or fatter than the right tail.
- Symmetric: Both tails are of the same length.
Example: In a right-skewed distribution, most data points are concentrated on the left, with a few high values stretching to the right.
2. Kurtosis: Kurtosis measures the “tailedness” of the data distribution. It indicates how the tails of the distribution differ from the tails of a normal distribution.
- Leptokurtic: High kurtosis, indicating heavy tails.
- Platykurtic: Low kurtosis, indicating light tails.
- Mesokurtic: Similar kurtosis to a normal distribution.
Example: A leptokurtic distribution has more extreme outliers than a normal distribution, while a platykurtic distribution has fewer.
By understanding these concepts and utilizing appropriate visualizations, students can gain deeper insights into their data, making the EDA process more effective and engaging.
Data Visualization Techniques
Effective data visualization is crucial for understanding and interpreting data. It helps to reveal patterns, trends, and insights that might not be immediately apparent. In this section, we will explore various data visualization techniques, categorized into univariate, bivariate, and multivariate analysis.
Univariate Analysis
Univariate analysis focuses on a single variable at a time. Here are two common visualization techniques used in univariate analysis:
Histograms
A histogram is a graphical representation that organizes a group of data points into user-specified ranges. It is useful for understanding the distribution of a dataset.
Example: Consider a dataset of students’ exam scores.
Python code
import matplotlib.pyplot as plt
import numpy as np
# Sample data
scores = np.random.normal(70, 10, 100)
# Creating the histogram
plt.hist(scores, bins=10, edgecolor=’black’)
plt.title(‘Histogram of Exam Scores’)
plt.xlabel(‘Score’)
plt.ylabel(‘Frequency’)
plt.show()
Box Plots
A box plot (or box-and-whisker plot) displays the distribution of a dataset based on a five-number summary: minimum, first quartile, median, third quartile, and maximum.
Example: Using the same dataset of students’ exam scores.
Python code
# Creating the box plot
plt.boxplot(scores)
plt.title(‘Box Plot of Exam Scores’)
plt.ylabel(‘Score’)
plt.show()
Bivariate Analysis
Bivariate analysis involves the analysis of two variables to understand the relationship between them.
Scatter Plots
A scatter plot displays values for two variables for a set of data. It is useful for identifying relationships and correlations between variables.
Example: Consider a dataset of students’ hours studied and their corresponding exam scores.
Python code
# Sample data
hours_studied = np.random.normal(5, 2, 100)
exam_scores = hours_studied * 10 + np.random.normal(50, 10, 100)
# Creating the scatter plot
plt.scatter(hours_studied, exam_scores)
plt.title(‘Scatter Plot of Hours Studied vs. Exam Scores’)
plt.xlabel(‘Hours Studied’)
plt.ylabel(‘Exam Score’)
plt.show()
Correlation Matrices
A correlation matrix is a table showing correlation coefficients between variables. Each cell in the table shows the correlation between two variables.
Example: Using a dataset with multiple variables (e.g., hours studied, exam scores, and class attendance).
python code
import seaborn as sns
import pandas as pd
# Sample data
data = {
‘Hours_Studied’: hours_studied,
‘Exam_Scores’: exam_scores,
‘Class_Attendance’: np.random.normal(75, 15, 100)
}
df = pd.DataFrame(data)
# Creating the correlation matrix
correlation_matrix = df.corr()
# Creating the heatmap
sns.heatmap(correlation_matrix, annot=True, cmap=’coolwarm’)
plt.title(‘Correlation Matrix’)
plt.show()
Multivariate Analysis
Multivariate analysis involves the analysis of more than two variables to understand relationships in complex datasets.
Pair Plots
A pair plot (or scatterplot matrix) shows the pairwise relationships between different variables in a dataset.
Example: Using the same dataset with multiple variables.
Python code
# Creating the pair plot
sns.pairplot(df)
plt.title(‘Pair Plot’)
plt.show()
Heatmaps
A heatmap is a graphical representation of data where individual values are represented as colors. It is useful for identifying patterns and correlations in large datasets.
Example: Using the correlation matrix created earlier.
python code
# Creating the heatmap
sns.heatmap(correlation_matrix, annot=True, cmap=’viridis’)
plt.title(‘Heatmap of Correlation Matrix’)
plt.show()
Understanding and effectively utilizing data visualization techniques are essential skills for students and professionals working with data. By mastering these techniques, you can uncover deeper insights and communicate your findings more clearly and compellingly. These examples and visual representations aim to provide a practical and engaging approach to learning data visualization.
Data Cleaning and Preparation
Data cleaning and preparation is a critical step in the data preprocessing phase, essential for ensuring the quality and usability of data for analysis and modeling. This process involves several key tasks: handling missing values, dealing with outliers, normalizing and scaling data, and encoding categorical variables.
Handling Missing Values
Missing data can significantly impact the results of data analysis and machine learning models. There are several techniques to handle missing values:
Removing Missing Values: This is the simplest method where rows or columns with missing values are removed. This approach is feasible when the proportion of missing data is small.
Example:
Python code
import pandas as pd
df = pd.DataFrame({
‘Name’: [‘Alice’, ‘Bob’, ‘Charlie’, ‘David’],
‘Age’: [24, None, 22, 32],
‘Score’: [85, 90, None, 88]
})
df_cleaned = df.dropna()
print(df_cleaned)
Output:
| Name | Age | Score | |
| 0 | Alice | 24.0 | 85.0 |
Imputation: This involves filling missing values with a specific value like the mean, median, mode, or value predicted by a model.
Example:
Python code
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy=’mean’)
df[‘Age’] = imputer.fit_transform(df[[‘Age’]])
df[‘Score’] = imputer.fit_transform(df[[‘Score’]])
print(df)
Output:
| Name | Age | Score | |
| 0 | Alice | 24.0 | 85.0 |
| 1 | Bob | 26.0 | 90.0 |
| 2 | Charlie | 22.0 | 87.67 |
| 3 | David | 32.0 | 88.0 |
Predictive Modeling: Advanced techniques like using machine learning algorithms to predict and fill in missing values based on other available data.
Dealing with Outliers
Outliers are extreme values that differ significantly from other observations in the dataset. They can distort statistical analyses and machine learning models. Techniques to handle outliers include:
Removing Outliers: Identifying and removing outliers can be done using statistical methods or visualization techniques like box plots.
Example:
Python code
import numpy as np
df[‘Age’] = np.where(df[‘Age’] > 30, np.nan, df[‘Age’])
df = df.dropna()
print(df)
Output:
| Name | Age | Score | |
| 0 | Alice | 24.0 | 85.0 |
| 2 | Charlie | 22.0 | 87.67 |
Transforming Data: Applying transformations such as log or square root can reduce the impact of outliers.
Example:
Python code
df[‘Score’] = np.log(df[‘Score’])
print(df)
Output:
| Name | Age | Score | |
| 0 | Alice | 24.0 | 4.4427 |
| 2 | Charlie | 22.0 | 4.4760 |
Normalizing and Scaling Data
Normalization and scaling are techniques to adjust the range and distribution of data features. This process is essential for algorithms that are sensitive to the scale of data.
Normalization: Rescaling the data to a range of [0, 1] or [-1, 1].
Example:
Python code
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df[[‘Age’, ‘Score’]] = scaler.fit_transform(df[[‘Age’, ‘Score’]])
print(df)
Output:
| Name | Age | Score | |
| 0 | Alice | 1.0 | 0.000000 |
| 2 | Charlie | 0.0 | 0.681325 |
Standardization: Scaling data to have a mean of 0 and a standard deviation of 1.
Example:
Python code
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[[‘Age’, ‘Score’]] = scaler.fit_transform(df[[‘Age’, ‘Score’]])
print(df)
Output:
| Name | Age | Score | |
| 0 | Alice | 0.7071 | -1.0000 |
| 2 | Charlie | -0.7071 | 1.0000 |
Encoding Categorical Variables
Categorical variables need to be converted into numerical values for machine learning algorithms. Common techniques include:
Label Encoding: Converting categorical values into integer codes.
Example:
Python code
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df[‘Name’] = le.fit_transform(df[‘Name’])
print(df)
Output:
| Name | Age | Score | |
| 0 | 0 | 0.7071 | -1.0000 |
| 2 | 1 | -0.7071 | 1.0000 |
One-Hot Encoding: Creating binary columns for each category.
Example:
Python code
df = pd.get_dummies(df, columns=[‘Name’])
print(df)
Output:
| Age | Score | Name_0 | Name_1 | |
| 0 | 0.7071 | -1.0000 | 1 | 0 |
| 2 | -0.7071 | 1.0000 | 0 | 1 |
By following these data cleaning and preparation techniques, students can ensure their datasets are ready for analysis and modeling, leading to more accurate and reliable results.

Case Studies and Real-Time Examples in Data Analysis
1. Retail Data Analysis:
Retail data analysis involves using customer transaction data to derive insights that improve business operations and customer experience. For example:
- Customer Segmentation: Analyzing purchase history to segment customers based on buying behavior, demographics, and preferences. Pictorial representation could include a clustering diagram showing different customer segments based on spending habits and age groups.
- Inventory Management: Using sales data to optimize inventory levels, reduce stockouts, and improve supply chain efficiency. An example could be a graph showing seasonal demand patterns influencing inventory stocking decisions.
2. Healthcare Data Analysis:
Healthcare data analysis focuses on improving patient outcomes and operational efficiencies in hospitals and clinics. For instance:
- Clinical Decision Support: Analyzing patient data to assist doctors in diagnosing diseases and recommending treatments. A pictorial representation might include a flowchart of decision-making based on patient symptoms and medical history.
- Healthcare Cost Analysis: Using billing and claims data to identify cost-saving opportunities and optimize resource allocation. An example could be a comparative cost analysis graph showing trends in treatment costs over time.
3. Financial Data Analysis:
Financial data analysis involves analyzing financial statements, market data, and economic indicators to make informed investment decisions. For example:
- Risk Assessment: Using historical market data to assess investment risks and predict market trends. A pictorial representation could include a risk matrix showing different levels of financial risk associated with investment options.
- Portfolio Optimization: Analyzing asset performance to create diversified investment portfolios that maximize returns and minimize risks. An example could be an efficient frontier graph illustrating optimal portfolio combinations based on risk and return.
4. Social Media Data Analysis:
Social media data analysis focuses on understanding user behavior and optimizing marketing strategies on platforms like Facebook, Twitter, and Instagram. For instance:
- Sentiment Analysis: Analyzing social media posts to gauge public opinion and sentiment towards a brand or product. A pictorial representation might include a sentiment timeline showing shifts in public sentiment over a campaign period.
- User Engagement Analysis: Using engagement metrics (likes, shares, comments) to measure the effectiveness of social media campaigns. An example could be a bar chart comparing engagement rates across different types of content.
Practical Insights and Takeaways:
- Importance of Data Quality: Highlight the significance of clean, reliable data for accurate analysis in each sector.
- Visualization Techniques: Emphasize the use of charts, graphs, and diagrams to visualize complex data patterns and insights effectively.
- Business Impact: Discuss how data analysis in these sectors leads to improved decision-making, cost savings, and enhanced customer satisfaction.
Advanced EDA Techniques
1. Principal Component Analysis (PCA)
Principal Component Analysis is a dimensionality reduction technique used to simplify complex datasets. For example, in healthcare analytics, PCA can be applied to patient health records to identify the most significant factors affecting patient outcomes, such as age, medical history, and lifestyle habits. This technique helps in visualizing patient clusters based on similar characteristics, aiding in personalized treatment plans.
2. Clustering Techniques
Clustering methods like K-means clustering are used to group similar data points together. In retail, clustering can segment customers based on purchasing behavior. For instance, analyzing transaction data can reveal customer segments such as frequent shoppers, seasonal buyers, and occasional visitors, helping retailers tailor marketing strategies accordingly.
3. Time Series Analysis
Time Series Analysis is used to analyze data points collected at regular intervals over time. For instance, in financial markets, analyzing stock price movements over the years can help predict future trends and make informed investment decisions. Techniques like ARIMA (AutoRegressive Integrated Moving Average) are commonly used for forecasting in such scenarios.
4. Anomaly Detection
Anomaly Detection identifies unusual patterns or outliers in data. In cybersecurity, anomaly detection algorithms monitor network traffic to detect abnormal activities like unauthorized access attempts or malware infections. This helps in preventing cyberattacks and ensuring data security.
Common Challenges in EDA
- Handling Large Datasets
- Dealing with large datasets involves efficient storage, processing, and analysis techniques. For example, in social media analytics, handling vast amounts of user-generated content requires scalable data processing frameworks like Apache Hadoop or Apache Spark.
- Dealing with Noisy Data
- Noisy data, such as incomplete or inaccurate data points, can affect analysis outcomes. In healthcare diagnostics, noisy sensor data from medical devices can lead to erroneous patient health assessments. Preprocessing techniques like data cleaning and outlier removal are crucial to ensure data quality.
- Balancing Between Underfitting and Overfitting
- In machine learning models, finding the right balance between underfitting (high bias) and overfitting (high variance) is critical. For example, in predictive analytics for weather forecasting, a model that underfits may oversimplify weather patterns, while an overfitted model may perform well on historical data but fail to generalize to new weather conditions.
EDA in the Context of Machine Learning
Exploratory Data Analysis (EDA) plays a crucial role in the success of machine learning projects. It involves understanding the data, identifying patterns, and extracting insights that can guide the modeling process effectively. Here’s how EDA intersects with various stages of machine learning:
Feature Selection EDA helps in identifying the most relevant features for building robust machine learning models. By analyzing relationships between features and the target variable, EDA guides feature selection techniques such as:
- Correlation Analysis: Understanding how features correlate with each other and with the target variable helps in selecting the most predictive features.
- Univariate Analysis: Examining the distribution and statistics of individual features to determine their importance.
Example: In a healthcare dataset aiming to predict patient outcomes, EDA might reveal that certain demographic features (age, gender) and medical history variables (cholesterol levels, blood pressure) have the strongest correlations with the target variable (e.g., risk of developing a specific disease).
Data Preprocessing for Model Building EDA highlights data preprocessing steps necessary to prepare data for modeling. This includes handling missing values, and outliers, and ensuring data quality through techniques like:
- Data Imputation: EDA guides decisions on how to fill missing data points based on patterns observed in existing data.
- Outlier Detection: Identifying outliers that could skew model performance and deciding whether to remove or transform them.
Example: In a financial dataset for predicting stock prices, EDA might reveal outliers in trading volumes during market crashes. Understanding these anomalies helps in deciding whether to filter them out or transform them appropriately.
Understanding Model Assumptions EDA helps validate assumptions underlying machine learning models. By visualizing relationships and distributions, EDA ensures that:
- Assumptions like Normality and Linearity: EDA checks whether data aligns with assumptions made by models like linear regression or Gaussian Naive Bayes.
- Model Feasibility: EDA identifies whether the dataset meets requirements for using specific models, such as balanced classes for classification tasks.
Example: In a marketing dataset for predicting customer churn, EDA might reveal that the distribution of customer engagement metrics follows a non-linear pattern. This insight prompts consideration of non-linear models like decision trees or neural networks.
Conclusion
In conclusion, Exploratory Data Analysis (EDA) serves as a cornerstone in the machine learning pipeline, offering critical insights that shape feature selection, data preprocessing, and model assumptions. By leveraging EDA effectively, data scientists can enhance model accuracy and reliability, ultimately driving informed decision-making across various domains.
Summary of Key Points
- EDA helps in identifying predictive features through techniques like correlation analysis and univariate analysis.
- It guides data preprocessing by handling missing values, and outliers, and validating assumptions crucial for model building.
- Understanding model assumptions ensures alignment between data characteristics and model requirements, enhancing model performance.
Future Trends in EDA
The future of EDA lies in advanced techniques such as:
- Interactive Visualization: Tools that allow real-time exploration and manipulation of data visualizations.
- Automated EDA: Machine learning algorithms that automate the discovery of patterns and insights from large datasets.
- Integration with AI: EDA techniques integrated into AI systems for continuous learning and adaptive analytics.
Exploratory Data Analysis (EDA) is a crucial step in data analysis that involves studying, exploring, and visualizing data to derive insights. Key concepts include descriptive statistics, data visualization, EDA analysis, and outlier detection. Popular tools include Python libraries like Pandas and Matplotlib and R packages like dplyr and ggplot2. EDA is essential for successful machine learning projects. Click here to learn more about Trizula Mastery in Data Science, a self-paced program that equips IT students with essential data science skills.

1. What is meant by exploratory data analysis?
Exploratory data analysis (EDA) is a process of examining and summarizing data to understand its structure, patterns, and relationships. It involves using various statistical and graphical techniques to gain insights into the data and identify potential issues or anomalies.
2. What is data exploration analysis?
Data exploration analysis is another term for exploratory data analysis (EDA). It is a systematic process of examining and summarizing data to understand its characteristics, identify patterns, and detect anomalies.
3. What is EDA used for?
Exploratory data analysis (EDA) is used to gain a deeper understanding of the data, identify potential issues or anomalies, and prepare it for further analysis or modeling. It helps in identifying the most important variables, checking for missing values, and ensuring data quality.
4. What is an example of EDA?
An example of EDA is examining the distribution of a variable, such as the age of customers, to understand its range and any potential outliers. This can be done using statistical measures like mean, median, and standard deviation, as well as visualizations like histograms and box plots.
5. What are the steps of EDA?
The steps of exploratory data analysis (EDA) typically include:
- Data Cleaning: Ensuring the data is accurate, complete, and free of errors.
- Data Summarization: Calculating summary statistics like mean, median, and standard deviation.
- Data Visualization: Using plots and charts to visualize the data and identify patterns.
- Data Transformation: Transforming the data to make it more suitable for analysis.
- Data Modeling: Identifying relationships between variables and creating models to describe the data.


