
Target Audience: The primary target audience for this comprehensive article on SQLite and SQLAlchemy in Python includes Python developers, data analysts, data scientists, and students or learners interested in expanding their knowledge of Python’s database capabilities. Python developers will find this guide valuable as they seek to effectively use SQLite and SQLAlchemy in their projects, from beginner to advanced levels. Data analysts and data scientists who work with data and need to interact with databases using Python will also benefit from the insights provided, as they look to leverage the power of SQLite and SQLAlchemy. Additionally, students and other learners interested in gaining practical experience with SQLite and SQLAlchemy will find this guide to be a valuable resource.
Value Proposition: This article offers a comprehensive and practical approach to SQLite and SQLAlchemy, providing significant value to the target audience. It offers a detailed and structured overview of these technologies, covering a wide range of topics from the basics to advanced concepts. The guide’s hands-on approach, with numerous examples and real-world applications, allows readers to gain practical experience and apply the concepts directly to their projects. By mastering SQLite and SQLAlchemy, readers will be able to build more efficient and robust Python applications that interact with databases effectively, leading to improved productivity and efficiency. Furthermore, acquiring proficiency in SQLite and SQLAlchemy can be a valuable skill for Python developers, data analysts, and data scientists, enhancing their career prospects and opportunities.
Key Takeaways: After reading this article, the target audience can expect to gain several key takeaways. Firstly, they will develop a comprehensive understanding of SQLite, a lightweight and embedded database, and SQLAlchemy, a powerful Python SQL toolkit and Object-Relational Mapping (ORM) library. Secondly, they will learn how to perform basic database operations, such as creating tables, inserting, updating, and querying data, using both SQLite and SQLAlchemy. Thirdly, readers will dive deep into SQLAlchemy, learning about its core components, the ORM, and how to leverage its advanced features for efficient database interactions. Additionally, the guide will provide insights on integrating SQLite and SQLAlchemy in their Python projects, as well as explore best practices, performance considerations, and optimization techniques. The guide also includes practical examples and case studies, allowing readers to apply the learned concepts to their data-driven projects, whether in the context of web development, data analysis, or data science. Finally, the target audience will learn about testing and debugging techniques for SQLite and SQLAlchemy applications, as well as strategies for deploying and scaling their database-driven Python projects.
Python SQLite and SQLAlchemy: Introduction Fundamentals
SQLite and SQLAlchemy are essential tools for Python developers working with databases. SQLite is a lightweight, disk-based database that doesn’t require a separate server, making it perfect for local data storage and small applications. SQLAlchemy, on the other hand, is an ORM (Object Relational Mapper) that simplifies database interactions by allowing developers to work with Python objects instead of raw SQL. Together, they streamline database management and enhance productivity in Python programming.
Overview of SQLite and SQLAlchemy
SQLite is a lightweight, serverless, and self-contained SQL database engine that is widely used in various applications, including mobile apps, embedded systems, and desktop programs. It is known for its simplicity, ease of use, and small footprint, making it an ideal choice for projects with limited resources.
SQLAlchemy, on the other hand, is a Python SQL toolkit and Object-Relational Mapping (ORM) library that provides a high-level abstraction for interacting with databases. It supports a wide range of database engines, including SQLite, MySQL, PostgreSQL, Oracle, and more. SQLAlchemy simplifies database operations by providing a consistent API for performing common tasks such as querying, inserting, updating, and deleting data.
Python SQLite and SQLAlchemy: Unlocking Database Benefits
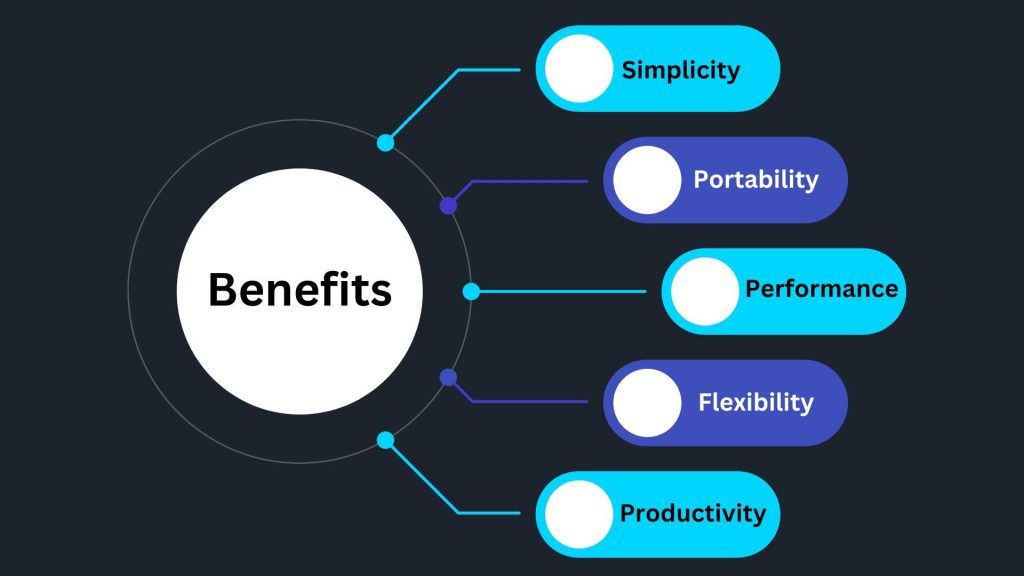
Using SQLite and SQLAlchemy in your Python projects offers several benefits:
- Simplicity: SQLite is easy to set up and use, requiring minimal configuration and no separate server process.
- Portability: SQLite databases are stored in a single file, making them portable across different platforms and easy to distribute with your application.
- Performance: SQLite is designed to be fast and efficient, providing good performance for most use cases.
- Flexibility: SQLAlchemy supports a wide range of database engines, allowing you to easily switch between different databases without modifying your code.
- Productivity: SQLAlchemy’s ORM layer abstracts away many low-level database details, allowing you to focus on writing application logic rather than dealing with database-specific code.
Comparison of SQLite and SQLAlchemy
While SQLite and SQLAlchemy are often used together, they serve different purposes:
- SQLite is a database engine that provides a lightweight and embedded SQL database solution.
- SQLAlchemy is a Python library that provides a high-level abstraction for interacting with databases, including SQLite and other database engines.
SQLite is a great choice for projects that require a simple, embedded database, while SQLAlchemy is useful for projects that need to interact with various database engines or require more advanced features such as connection pooling, transactions, and schema management.
By understanding the relationship between SQLite and SQLAlchemy, you can make informed decisions about which tools to use in your Python projects based on your specific requirements and constraints.
In the following sections, we’ll dive deeper into the practical aspects of using SQLite and SQLAlchemy in your engineering projects, providing hands-on examples and best practices to help you become proficient in these technologies.
SQLite Basics for Beginners Using Python Programming
SQLite is a lightweight, serverless relational database management system (RDBMS) that can be easily integrated into Python applications. It’s perfect for projects that require a simple and efficient database solution without the overhead of a full-scale RDBMS like MySQL or PostgreSQL. SQLite requires no server setup, making it ideal for small to medium applications. Using Python’s built-in SQLite3 module, you can create databases, execute SQL queries, and manage data seamlessly. The process includes connecting to a database, creating tables, inserting data, and performing queries, providing a practical foundation for database management in Python projects.
Installing SQLite in Python
SQLite is a built-in module in Python, so you don’t need to install any additional packages to use it. However, you may need to install the SQLite command-line tool, which provides a convenient way to interact with SQLite databases. The process for installing SQLite varies depending on your operating system, but you can usually find the appropriate instructions online.
Once you have SQLite installed, you can start using it in your Python projects by importing the sqlite3 module:
import sqlite3
Connecting to a SQLite Database
To connect to an SQLite database, you can use the sqlite3.connect() function. If the database file doesn’t exist, it will be created automatically:
conn = sqlite3.connect(‘example.db’)
You can also use the :memory: keyword to create an in-memory database, which is useful for testing and prototyping:
conn = sqlite3.connect(‘:memory:’)
Creating Tables and Managing Schema
Once you have a connection to the database, you can start creating tables and managing the schema. Here’s an example of how to create a simple table:
# Create a cursor object
cursor = conn.cursor()
# Create a table
cursor.execute(“””
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT,
email TEXT
)
“””)
# Commit the changes
conn.commit()
In this example, we first create a cursor object, which allows us to execute SQL commands. We then use the cursor.execute() method to create a table named users with three columns: id, name, and email.
To add more tables or modify the schema, you can simply execute additional SQL statements using the cursor object.
Pictorial Representation
To help you visualize the process, here’s a diagram that illustrates the steps we’ve covered so far:
| Step | Description |
| 1 | Python Program |
| 2 | sqlite3 Module |
| 3 | SQLite Database |
| 4 | Users Table |
The diagram illustrates the following steps:
- The Python program interacts with the sqlite3 module.
- The SQLite3 module is used to connect to the SQLite database.
- The SQLite database is created and managed.
- The user’s table is created within the SQLite database.
This diagram shows how the Python program interacts with the SQLite3 module to connect to a SQLite database and create a table named users.
By following the steps outlined in this section, you’ll be well on your way to mastering the basics of working with SQLite in your Python projects. In the next section, we’ll explore more advanced operations, such as inserting, querying, updating, and deleting data.
Basic Operations with SQLite
Basic operations with SQLite involve creating, reading, updating, and deleting data in a lightweight, self-contained database. Using SQL commands, you can create tables, insert records, query data, and perform transactions. SQLite’s simplicity and serverless architecture make it ideal for embedded systems, mobile apps, and small to medium-sized projects. Now that you’ve learned how to set up an SQLite database and create tables, let’s dive into the basic operations you’ll need to perform when working with data in SQLite. In this section, we’ll cover inserting data, querying data, and updating and deleting data.
Inserting Data into SQLite Tables
To insert data into a SQLite table, you can use the INSERT INTO statement. Here’s an example:
# Insert a single row
cursor.execute(“INSERT INTO users (name, email) VALUES (?, ?)”, (‘John Doe’, ‘john.doe@example.com’))
# Insert multiple rows
data = [
(‘Jane Smith’, ‘jane.smith@example.com’),
(‘Bob Johnson’, ‘bob.johnson@example.com’),
(‘Alice Williams’, ‘alice.williams@example.com’)
]
cursor.executemany(“INSERT INTO users (name, email) VALUES (?, ?)”, data)
# Commit the changes
conn.commit()
In this example, we first insert a single row using the cursor.execute() method. We then insert multiple rows using the cursor.executemany() method, which takes a list of data as input.
Querying Data from SQLite Tables
To retrieve data from a SQLite table, you can use the SELECT statement. Here’s an example:
# Select all rows from the user’s table
cursor.execute(“SELECT * FROM users”)
all_rows = cursor.fetchall()
for row in all_rows:
print(row)
# Select specific columns and filter the results
cursor.execute(“SELECT name, email FROM users WHERE id > ?”, (1,))
filtered_rows = cursor.fetchall()
for row in filtered_rows:
print(row)
In this example, we first select all rows from the users table using cursor.execute() and cursor.fetchall(). We then select specific columns (name and email) and filter the results based on the id column.
Updating and Deleting Data in SQLite
To update data in a SQLite table, you can use the UPDATE statement. Here’s an example:
# Update a row
cursor.execute(“UPDATE users SET email = ? WHERE id = ?”, (‘new.email@example.com’, 1))
conn.commit()
# Delete a row
cursor.execute(“DELETE FROM users WHERE id = ?”, (2,))
conn.commit()
In this example, we first update the email column for the row with id = 1. We then delete the row with id = 2.
Remember to call Conn.commit() after any data modification operations to ensure the changes are persisted to the database.
By understanding these basic operations, you’ll be well-equipped to work with SQLite in your Python projects, whether you’re building a simple application or a more complex data-driven system.
Understanding SQLAlchemy
SQLAlchemy is a powerful Python SQL toolkit and Object-Relational Mapping (ORM) library that provides a high-level abstraction for interacting with databases. It supports a wide range of database engines, including SQLite, MySQL, PostgreSQL, Oracle, and more. In this section, we’ll dive into the core concepts of SQLAlchemy and how to set it up in your Python projects.
Introduction to SQLAlchemy ORM (Object-Relational Mapping)
The SQLAlchemy ORM is a powerful tool that allows you to map Python classes to database tables, making it easier to work with data in an object-oriented way. With the ORM, you can define your database schema using Python classes and use those classes to interact with the database, without having to write raw SQL queries.
Here’s an example of how you might define a User class using the SQLAlchemy ORM:
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
In this example, we define a User class that inherits from the Base class provided by SQLAlchemy. We use the Column class to define the columns of the user table and specify the data types for each column.
SQLAlchemy Core vs ORM
SQLAlchemy consists of two main components: the Core and the ORM. The Core provides a set of low-level APIs for working with databases, while the ORM provides a higher-level abstraction for working with data in an object-oriented way.
The Core is useful for writing raw SQL queries and performing low-level database operations, while the ORM is better suited for working with data in an object-oriented way and performing common CRUD (Create, Read, Update, Delete) operations.
Here’s an example of how you might use the SQLAlchemy Core to execute a raw SQL query:
from sqlalchemy import create_engine, text
engine = create_engine(‘sqlite:///example.db’)
with engine.connect() as conn:
result = conn.execute(text(“SELECT * FROM users WHERE id = :id”), {“id”: 1})
for row in result:
print(row)
In this example, we use the create_engine function to create a connection to an SQLite database, and then use the execute method to execute a raw SQL query that selects all rows from the user’s table where the id column is equal to 1.
Setting up SQLAlchemy in Python Projects
To set up SQLAlchemy in your Python projects, you’ll need to install the sqlalchemy package using pip:
pip install sqlalchemy
Once you’ve installed SQLAlchemy, you can create a connection to your database using the create_engine function:
from sqlalchemy import create_engine
engine = create_engine(‘sqlite:///example.db’)
You can then use this engine to create a session and start interacting with the database using the SQLAlchemy ORM:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
user = User(name=’John Doe’, email=’john.doe@example.com’)
session.add(user)
session.commit()
In this example, we create a session using the sessionmaker function and then use that session to create a new User object and persist it to the database.
The ORM provides a high-level abstraction that allows you to work with data in an object-oriented way, without having to worry about the low-level details of interacting with the database. By understanding the core concepts of SQLAlchemy and how to set it up in your Python projects, you’ll be well on your way to building powerful, data-driven applications that leverage the power of relational databases.
Working with SQLAlchemy Core
While the SQLAlchemy ORM provides a high-level abstraction for working with databases, the SQLAlchemy Core offers a more low-level and flexible approach. In this section, we’ll explore how to use the SQLAlchemy Core to create tables, perform CRUD (Create, Read, Update, Delete) operations, and execute raw SQL queries.
Creating Tables using SQLAlchemy Core
To create tables using the SQLAlchemy Core, you can use the Table class and define the table structure directly in your Python code. Here’s an example:
from sqlalchemy import Table, Column, Integer, String, MetaData
metadata = MetaData()
users_table = Table(
‘users’, metadata,
Column(‘id’, Integer, primary_key=True),
Column(‘name’, String),
Column(’email’, String)
)
In this example, we create a Table object named users_table that represents the user’s table in the database. We define the columns using the Column class, specifying the data types and constraints (such as the primary key).
Inserting, Updating, and Deleting Data with SQLAlchemy Core
To perform CRUD operations using the SQLAlchemy Core, you can use the insert(), update(), and delete() methods provided by the Table object. Here are some examples:
# Insert data
insert_stmt = users_table.insert().values(name=’John Doe’, email=’john.doe@example.com’)
with engine.connect() as conn:
conn.execute(insert_stmt)
# Update data
update_stmt = users_table.update().where(users_table.c.id == 1).values(email=’new.email@example.com’)
with engine.connect() as conn:
conn.execute(update_stmt)
# Delete data
delete_stmt = users_table.delete().where(users_table.c.id == 2)
with engine.connect() as conn:
conn.execute(delete_stmt)
In these examples, we use the insert(), update(), and delete() methods to create the corresponding SQL statements, and then execute them using the execute() method of the database connection.
Executing Raw SQL Queries with SQLAlchemy Core
The SQLAlchemy Core also allows you to execute raw SQL queries directly. This can be useful when you need to perform complex or custom database operations that are not easily expressed using the ORM. Here’s an example:
from sqlalchemy import text
# Execute a raw SQL query
with engine.connect() as conn:
result = conn.execute(text(“SELECT * FROM users WHERE id > :id”), {“id”: 1})
for row in result:
print(row)
In this example, we use the text() function to create a SQL expression, and then execute it using the execute() method of the database connection. We can also pass parameters to the SQL query using a dictionary.
The SQLAlchemy Core provides a lower-level and more flexible API for working with databases, allowing you to execute raw SQL queries, create and manage tables, and perform CRUD operations. By understanding the SQLAlchemy Core and how to use it in your Python projects, you’ll be able to tackle more complex database-related tasks and gain a deeper understanding of how databases work under the hood.
Using SQLAlchemy ORM
In the previous section, we explored the SQLAlchemy Core, which provides a low-level and flexible API for working with databases. In this section, we’ll dive into the SQLAlchemy ORM (Object-Relational Mapping), which offers a higher-level abstraction for interacting with databases in an object-oriented way.
Declaring Models and Mapping to Database Tables
The SQLAlchemy ORM allows you to define your database schema using Python classes, known as models. These models are then mapped to the corresponding database tables. Here’s an example of how you might define a User model:
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
def __repr__(self):
return f”User(id={self.id}, name='{self.name}’, email='{self.email}’)”
In this example, we define a User class that inherits from the Base class provided by SQLAlchemy. We use the Column class to define the columns of the user table and specify the data types for each column. We also define a __repr__ method to provide a string representation of the User object.
Querying Data with SQLAlchemy ORM
Once you’ve defined your models, you can use the SQLAlchemy ORM to query data from the database. Here’s an example:
from sqlalchemy.orm import Session
# Create a session
session = Session(bind=engine)
# Query all users
all_users = session.query(User).all()
for user in all_users:
print(user)
# Query users with a specific email
user = session.query(User).filter_by(email=’john.doe@example.com’).first()
print(user)
In this example, we create a Session object and use the query() method to retrieve data from the user’s table. We can filter the results using the filter_by() method, and retrieve a single row using the first() method.
Relationships and Joins in SQLAlchemy ORM
The SQLAlchemy ORM also supports defining relationships between models, which allows you to perform more complex queries and join data from multiple tables. Here’s an example of how you might define a one-to-many relationship between User and Post models:
from sqlalchemy import Column, Integer, String, ForeignKey
from sqlalchemy.orm import relationship
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
posts = relationship(‘Post’, backref=’author’)
class Post(Base):
__tablename__ = ‘posts’
id = Column(Integer, primary_key=True)
title = Column(String)
body = Column(String)
user_id = Column(Integer, ForeignKey(‘users.id’))
In this example, we define a Post model that has a user_id column, which is a foreign key that references the id column in the user’s table. We also define a post-relationship on the User model, which allows us to access the posts associated with a particular user.
Here’s an example of how you might use this relationship to query data:
# Retrieve a user and their associated posts
user = session.query(User).filter_by(email=’john.doe@example.com’).first()
for post in user.posts:
print(f”{user.name} wrote: {post.title}”)
The SQLAlchemy ORM provides a higher-level abstraction for working with data in an object-oriented way, allowing you to define models that map to database tables and perform complex queries and data manipulations. By understanding the SQLAlchemy ORM and how to use it in your Python projects, you’ll be able to build more maintainable and scalable applications that interact with databases more intuitively and efficiently.
Advanced SQLAlchemy Concepts
As you become more proficient with SQLAlchemy, you’ll encounter more advanced concepts and techniques that can help you build more robust and efficient database-driven applications. In this section, we’ll explore some of these advanced topics, including transactions and session management, query optimization, and more.
Transactions and Session Management
Transactions are a fundamental concept in database management, ensuring that a series of database operations are executed as a single, atomic unit. SQLAlchemy provides a powerful session management system that makes it easy to work with transactions.
Here’s an example of how you might use transactions in your SQLAlchemy-powered application:
from sqlalchemy.orm import Session
# Create a session
session = Session(bind=engine)
# Begin a transaction
with session.begin():
# Perform database operations
user = User(name=’John Doe’, email=’john.doe@example.com’)
session.add(user)
# If any of the operations fail, the entire transaction will be rolled back
In this example, we use the session.begin() context manager to ensure that all the operations within the block are executed as a single transaction. If any of the operations fail, the entire transaction will be rolled back, ensuring data integrity.
Query Optimization Techniques in SQLAlchemy
SQLAlchemy provides several techniques for optimizing database queries, including lazy loading, eager loading, and query optimization. Here’s an example of how you might use eager loading to improve performance:
from sqlalchemy.orm import joinedload
# Retrieve users and their associated posts in a single query
users = session.query(User).options(joinedload(User.posts)).all()
for user in users:
for post in user.posts:
print(f”{user.name} wrote: {post.title}”)
In this example, we use the joinedload() option to eagerly load the posts relationship when querying for User objects. This can significantly improve performance compared to lazy loading, where the posts would be loaded on-demand.
Advanced ORM Features and Techniques
The SQLAlchemy ORM offers a wide range of advanced features and techniques that can help you build more sophisticated database-driven applications. Some examples include:
- Polymorphic Inheritance: Allows you to define inheritance relationships between models and query across them.
- Association Proxies: Provides a way to create virtual attributes that represent relationships between models.
- Hybrid Attributes: Allows you to define custom attributes that combine database and Python-based logic.
- Event Listeners: Provides a way to hook into various events in the SQLAlchemy lifecycle, such as object creation, updates, and deletions.
Here’s an example of how you might use a hybrid attribute to define a computed property:
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import relationship, hybrid_property
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
first_name = Column(String)
last_name = Column(String)
posts = relationship(‘Post’, backref=’author’)
@hybrid_property
def full_name(self):
return f”{self.first_name} {self.last_name}”
@full_name.expression
def full_name(cls):
return cls.first_name + ” ” + cls.last_name
In this example, we define a full_name hybrid attribute that combines the first_name and last_name columns into a single, computed property. This property can be used in queries and other parts of the application, providing a more intuitive way to work with user data.
The advanced SQLAlchemy concepts, such as transactions, session management, query optimization, and advanced ORM features, are all part of the SQLAlchemy ORM layer, providing a powerful and flexible way to work with databases in your Python applications. By mastering these advanced SQLAlchemy concepts, you’ll be able to build more robust, scalable, and efficient database-driven applications that can handle complex data requirements and performance challenges.
Integration of SQLite and SQLAlchemy
SQLite is a lightweight, serverless, and self-contained SQL database engine that is often used in conjunction with SQLAlchemy, a powerful Python SQL toolkit and Object-Relational Mapping (ORM) library. By integrating SQLite and SQLAlchemy, you can build efficient and robust database-driven applications in Python.
Using SQLite with SQLAlchemy ORM
To use SQLite with the SQLAlchemy ORM, you can define your database schema using Python classes, known as models. These models are then mapped to the corresponding SQLite database tables. Here’s an example of how you might define a User model:
from sqlalchemy import Column, Integer, String
from sqlalchemy.orm import declarative_base
Base = declarative_base()
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
In this example, we define a User class that inherits from the Base class provided by SQLAlchemy. We use the Column class to define the columns of the user table and specify the data types for each column.
Once you have defined your models, you can use the SQLAlchemy ORM to interact with the SQLite database. Here’s an example of how you might query data:
from sqlalchemy.orm import Session
# Create a session
session = Session(bind=engine)
# Query all users
all_users = session.query(User).all()
for user in all_users:
print(user)
In this example, we create a Session object and use the query() method to retrieve data from the user’s table.
Best Practices for Database Operations
When working with SQLite and SQLAlchemy, it’s important to follow best practices to ensure the reliability and efficiency of your database operations. Here are some key best practices to keep in mind:
- Use transactions: Wrap your database operations in transactions to ensure data consistency and integrity.
- Optimize queries: Use techniques like eager loading and query optimization to improve the performance of your queries.
- Handle errors: Implement proper error handling to gracefully handle exceptions that may occur during database operations.
- Use connection pooling: Enable connection pooling to efficiently manage database connections and improve performance.
- Follow naming conventions: Use consistent naming conventions for your tables, columns, and relationships to make your code more readable and maintainable.
Performance Considerations and Optimization Tips
While SQLite is generally fast and efficient, there are several ways to optimize the performance of your SQLite and SQLAlchemy-powered applications:
- Use indexes: Create indexes on columns that are frequently used in WHERE, ORDER BY, and JOIN clauses to speed up queries.
- Limit data returned: Use techniques like pagination and limiting the number of rows returned to reduce the amount of data transferred between the application and the database.
- Avoid unnecessary queries: Minimize the number of queries executed by using techniques like eager loading and batching.
- Use caching: Implement caching at various levels (e.g., query results, object instances) to reduce the load on the database.
- Monitor and profile: Monitor your application’s performance and use profiling tools to identify bottlenecks and optimize accordingly.
By following these best practices and optimization tips, you can build efficient and scalable applications that leverage the power of SQLite and SQLAlchemy.
The SQLAlchemy ORM provides a high-level abstraction for working with SQLite, allowing you to define models that map to database tables and perform complex queries and data manipulations. By understanding how to integrate SQLite and SQLAlchemy, and following best practices for database operations and performance optimization, you’ll be able to build efficient and scalable database-driven applications in Python.
Real-World Applications and Examples
As you’ve learned about SQLite and SQLAlchemy, it’s time to explore how these technologies can be applied in real-world scenarios. In this section, we’ll dive into practical examples and case studies to help you understand the versatility of these tools and how they can be leveraged in various applications.
Building a Python Application with SQLite and SQLAlchemy
One of the most common use cases for SQLite and SQLAlchemy is building a Python application that interacts with a database. Let’s consider a simple example of a task management application:
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.ext.declarative import declarative_base
# Set up the database connection
engine = create_engine(‘sqlite:///tasks.db’)
Session = sessionmaker(bind=engine)
Base = declarative_base()
# Define the Task model
class Task(Base):
__tablename__ = ‘tasks’
id = Column(Integer, primary_key=True)
title = Column(String)
description = Column(String)
status = Column(String)
# Create the database table
Base.metadata.create_all(engine)
# Interact with the database
session = Session()
# Add a new task
new_task = Task(title=’Finish report’, description=’Complete the quarterly report’, status=’Pending’)
session.add(new_task)
session.commit()
# Retrieve all tasks
all_tasks = session.query(Task).all()
for task in all_tasks:
print(f”ID: {task.id}, Title: {task.title}, Status: {task.status}”)
In this example, we define a Task model using the SQLAlchemy ORM, create an SQLite database, and perform basic CRUD (Create, Read, Update, Delete) operations on the tasks. This demonstrates how you can build a simple Python application that leverages SQLite and SQLAlchemy to manage data.
Case Studies of Using SQLite and SQLAlchemy in Data Science Projects
SQLite and SQLAlchemy are also widely used in data science projects, where the need to work with structured data is prevalent. Here’s an example of how you might use these tools in a data science project:
import pandas as pd
from sqlalchemy import create_engine
# Connect to the SQLite database
engine = create_engine(‘sqlite:///data.db’)
# Load data into a SQLite table
df = pd.DataFrame({‘name’: [‘John’, ‘Jane’, ‘Bob’], ‘age’: [30, 25, 35]})
df.to_sql(‘people’, engine, if_exists=’replace’, index=False)
# Perform data analysis using SQLAlchemy
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
average_age = session.execute(“SELECT AVG(age) AS avg_age FROM people”).scalar()
print(f”The average age is: {average_age}”)
In this example, we use Pandas to load data into a SQLite database using SQLAlchemy, and then perform a simple data analysis query using the SQLAlchemy ORM. This demonstrates how you can leverage the power of SQLite and SQLAlchemy in data science projects to store, manage, and analyze structured data.
Practical Examples of Database Interactions
To further illustrate the practical applications of SQLite and SQLAlchemy, let’s consider a few more examples:
- Web Application with SQLAlchemy ORM: Integrate SQLAlchemy with a web framework like Flask or Django to build a data-driven web application that interacts with an SQLite database.
- ETL Pipeline with SQLAlchemy Core: Use SQLAlchemy Core to build an Extract, Transform, and Load (ETL) pipeline that pulls data from various sources, transforms it, and loads it into a SQLite database.
- Serverless Application with SQLite: Deploy a serverless Python function (e.g., AWS Lambda) that uses SQLite and SQLAlchemy to store and retrieve data, taking advantage of SQLite’s lightweight and self-contained nature.
- Mobile App with SQLite: Embed a SQLite database in a mobile application (e.g., using the SQLite Python library for Android or iOS) to store and manage data locally on the device.
- Data Visualization with SQLAlchemy: Combine SQLAlchemy with data visualization libraries like Matplotlib or Plotly to create interactive dashboards and reports that leverage data stored in an SQLite database.
These examples demonstrate the versatility of SQLite and SQLAlchemy, and how they can be integrated into a wide range of Python-based applications and projects, from web development to data science and beyond.
By understanding these real-world examples and the integration of SQLite and SQLAlchemy, you’ll be better equipped to apply these technologies in your projects and solve a wide range of data-related challenges.
Testing and Debugging
As you build applications using SQLite and SQLAlchemy, it’s crucial to have a solid testing and debugging strategy in place. Testing ensures that your application works as expected, while debugging helps you identify and fix issues that arise during development and runtime. In this section, we’ll explore best practices and techniques for testing and debugging SQLite and SQLAlchemy-powered applications.
Unit Testing SQLAlchemy Applications
Unit testing is a crucial part of the development process, as it helps catch bugs early and ensures that your application’s components work as expected. When testing SQLAlchemy applications, you can use tools like SQLite’s in-memory database and mock objects to create isolated test environments.
Here’s an example of how you might write a unit test for a SQLAlchemy application:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from unittest.mock import patch
from your_app import User, create_user
# Set up the test database
engine = create_engine(‘sqlite:///:memory:’)
Session = sessionmaker(bind=engine)
def test_create_user():
# Create a mock session
session = Session()
# Patch the session creation
with patch(‘your_app.Session’, return_value=session):
# Call the create_user function
user = create_user(‘John Doe’, ‘john.doe@example.com’)
# Assert that the user was created correctly
assert user.name == ‘John Doe’
assert user.email == ‘john.doe@example.com’
assert session.query(User).count() == 1
In this example, we use SQLite’s in-memory database and mock objects to create a test environment for the create_user function. We patch the session creation to use our mock session and then assert that the user was created correctly and persisted to the database.
Debugging Techniques for SQLite and SQLAlchemy
When debugging SQLite and SQLAlchemy applications, it’s important to have a good understanding of the tools and techniques available. Here are some common debugging techniques:
- Logging: Use Python’s built-in logging module or a third-party logging library to log relevant information during the execution of your application.
- Profiling: Use profiling tools like cProfile or line_profiler to identify performance bottlenecks in your application.
- Breakpoints and Debuggers: Use breakpoints and debuggers like pdb or ipdb to step through your code and inspect variables during runtime.
- SQLite Command-line Tools: Use SQLite’s command-line tools to directly interact with the database and inspect its contents.
- SQLAlchemy Logging: Enable SQLAlchemy’s logging to see the SQL queries being executed and debug issues related to database interactions.
Error Handling in Database Operations
When working with databases, it’s important to handle errors gracefully and provide meaningful error messages to users. SQLAlchemy provides several exception classes that you can use to handle different types of errors.
Here’s an example of how you might handle a SQLAlchemyError exception:
from sqlalchemy.exc import SQLAlchemyError
try:
# Perform a database operation
user = User(name=’John Doe’, email=’john.doe@example.com’)
session.add(user)
session.commit()
except SQLAlchemyError as e:
# Handle the exception
error = str(e.__dict__[‘orig’])
print(f”Error occurred: {error}”)
session.rollback()
In this example, we wrap the database operation in a try-except block and catch any SQLAlchemyError exceptions that may occur. If an exception is raised, we print an error message and roll back the transaction to ensure data integrity.
The testing and debugging layer interacts with the Python application, SQLAlchemy, and the SQLite database to ensure that the application works as expected and to identify and fix any issues that arise during development and runtime. By incorporating unit testing, debugging techniques, and error handling into your development process, you can build more robust and reliable SQLite and SQLAlchemy-powered applications that provide a great user experience and minimize the impact of errors.
Deployment and Scaling
As you develop applications using SQLite and SQLAlchemy, it’s crucial to consider how you will deploy and scale your application to handle increasing amounts of data and traffic. In this section, we’ll explore deployment strategies, scaling considerations, and database migration techniques to help you build robust and scalable applications.
Deployment Strategies for SQLite and SQLAlchemy Applications
When deploying SQLite and SQLAlchemy applications, you have several options:
- Embedded SQLite: Deploy your application with an embedded SQLite database, which is suitable for small-scale applications or applications that don’t require a centralized database server.
- Serverless Deployment: Use serverless platforms like AWS Lambda or Google Cloud Functions to deploy your SQLite and SQLAlchemy applications, taking advantage of the scalability and ease of deployment offered by these services.
- Container-based Deployment: Package your application and its dependencies into a container using tools like Docker, making it easy to deploy and scale your application across different environments.
- Traditional Server Deployment: Deploy your application on a traditional server or virtual machine, either on-premises or in the cloud, and manage the SQLite and SQLAlchemy components as part of your application stack.
Scaling Considerations with SQLite and SQLAlchemy
When scaling your SQLite and SQLAlchemy applications, there are several factors to consider:
- Data Growth: As your application grows, the amount of data stored in the SQLite database will increase. You’ll need to monitor the database size and consider techniques like database sharding or partitioning to manage large datasets.
- Concurrency: If your application experiences high concurrency, with multiple users accessing and modifying data simultaneously, you’ll need to ensure that your application handles transactions and locking correctly to maintain data integrity.
- Caching: Implement caching strategies at various levels (e.g., application-level, database-level) to reduce the load on the SQLite database and improve response times for frequently accessed data.
- Horizontal Scaling: If your application requires more resources, consider scaling horizontally by adding more instances of your application behind a load balancer, allowing you to handle more traffic and requests.
Database Migration Techniques
As your application evolves, you may need to make changes to your database schema, such as adding new tables, modifying column definitions, or changing relationships between tables. SQLAlchemy provides several tools and techniques to help you manage database migrations:
- Alembic: Alembic is a database migration tool that integrates with SQLAlchemy. It allows you to generate migration scripts that describe the changes to your database schema, making it easy to apply these changes to your production database.
- Declarative Base: When using the SQLAlchemy ORM, you define your models using the declarative_base() function. This makes it easier to manage schema changes, as you can modify your model definitions and use Alembic to generate the necessary migration scripts.
- Database Versioning: SQLAlchemy supports database versioning, which allows you to track the changes made to your database schema over time. This can be useful for managing multiple environments (e.g., development, staging, production) and ensuring that each environment has the correct schema version.
- Database Backups: Regularly back up your SQLite database to ensure that you can restore your data in case of any issues or data loss. You can use tools like SQLite3 or third-party backup solutions to create and manage database backups.
By considering these deployment strategies, scaling factors, and database migration techniques, you can build SQLite and SQLAlchemy applications that are scalable, maintainable, and easy to deploy in various environments.
The deployment and scaling layer interacts with the Python application, SQLAlchemy, and the SQLite database to ensure that the application can be deployed in various environments and scaled to handle increasing amounts of data and traffic. By considering these deployment and scaling factors, you can build SQLite and SQLAlchemy applications that are robust, scalable, and easy to maintain over time.
Future Trends and Considerations
As Python continues to grow in popularity and data-driven applications become increasingly prevalent, it’s important to consider the future trends and evolving landscape of Python database development. In this section, we’ll explore some key areas to watch out for, including trends in Python database development, the evolution of SQLAlchemy and SQLite, and the integration of these technologies with big data and cloud services.
Trends in Python Database Development
Python’s versatility and ease of use have made it a popular choice for a wide range of applications, from web development to data science and machine learning. As a result, the demand for robust and scalable database solutions in Python has been steadily increasing. Some notable trends in Python database development include:
- Increased adoption of NoSQL databases: While relational databases like SQLite remain popular, there has been a growing interest in NoSQL databases, such as MongoDB and Cassandra, which offer flexible schema and scalability for handling large amounts of unstructured data.
- Rise of asynchronous programming: With the introduction of features like async/await in Python 3.5, there has been a shift towards asynchronous programming in database development. Frameworks like asyncio and libraries like aiohttp are being used to build highly concurrent and scalable applications.
- Emphasis on data science and machine learning: Python’s strong ecosystem of data science and machine learning libraries, such as NumPy, Pandas, and scikit-learn, has led to an increased focus on integrating database solutions with these tools for end-to-end data processing and analysis pipelines.
Evolution of SQLAlchemy and SQLite
SQLAlchemy and SQLite have been around for a while, but they continue to evolve and adapt to the changing needs of Python developers. Here are some notable developments in the evolution of these technologies:
- SQLAlchemy 2.0: The release of SQLAlchemy 2.0 brought several improvements, including better support for async/await, simplified configuration, and improved performance.
- SQLite 3.35.0: The latest version of SQLite, released in February 2021, introduced several new features, such as support for window functions, common table expressions (CTEs), and the ability to create virtual tables using SQL.
- Increased support for modern database features: Both SQLAlchemy and SQLite are continuously adding support for newer database features, such as JSON data types, full-text search, and spatial data handling, making them more versatile and suitable for a wider range of applications.
Integration with Big Data and Cloud Services
As data volumes continue to grow and the need for scalable and distributed data processing becomes more pressing, the integration of Python database solutions with big data and cloud services is becoming increasingly important. Some areas to watch out for include:
- Integration with big data frameworks: Python libraries like PyArrow and Deta are being used to integrate SQLAlchemy with big data frameworks like Apache Spark and Hadoop, enabling seamless data processing and analysis at scale.
- Serverless database solutions: Cloud providers like AWS, Google Cloud, and Microsoft Azure are offering serverless database solutions, such as Amazon Aurora Serverless, Google Cloud Spanner, and Azure Cosmos DB, which can be easily integrated with Python applications using libraries like SQLAlchemy.
- Hybrid cloud and multi-cloud architectures: As organizations adopt hybrid cloud and multi-cloud strategies, the need for database solutions that can operate across multiple cloud environments and on-premises infrastructure is increasing. SQLAlchemy’s database-agnostic design makes it well-suited for such scenarios.
By staying informed about these trends and developments, engineering students can better prepare themselves for the future of Python database development and build applications that are scalable, efficient, and future-proof.
Conclusion
In this comprehensive guide, we have explored the powerful combination of SQLite and SQLAlchemy in the context of Python development. As engineering students, understanding these technologies can provide you with a significant advantage in building robust, scalable, and efficient applications.
Summary of Key Concepts
Throughout this article, we have covered the following key concepts:
- Introduction to SQLite and SQLAlchemy: We provided an overview of SQLite, a lightweight and embedded database engine, and SQLAlchemy, a powerful Python SQL toolkit and Object-Relational Mapping (ORM) library.
- Getting Started with SQLite in Python: We walked through the process of installing SQLite, connecting to a database, and creating tables using Python.
- Basic Operations with SQLite: We demonstrated how to perform common database operations, such as inserting, querying, updating, and deleting data using SQLite.
- Understanding SQLAlchemy: We explored the SQLAlchemy ORM, which provides a high-level abstraction for working with databases, and the SQLAlchemy Core, which offers a more low-level and flexible approach.
- Advanced SQLAlchemy Concepts: We delved into more complex topics, including transactions, session management, query optimization, and advanced ORM features.
- Integration of SQLite and SQLAlchemy: We discussed best practices for using SQLite and SQLAlchemy together, as well as performance considerations and optimization techniques.
- Real-World Applications and Examples: We showcased how SQLite and SQLAlchemy can be applied in various scenarios, from building Python applications to data science projects.
- Testing and Debugging: We covered strategies for unit testing SQLAlchemy applications and techniques for debugging SQLite and SQLAlchemy-powered systems.
- Deployment and Scaling: We explored deployment strategies, scaling considerations, and database migration techniques to ensure your SQLite and SQLAlchemy applications can handle growing demands.
- Future Trends and Considerations: We discussed emerging trends in Python database development, the evolution of SQLAlchemy and SQLite, and the integration of these technologies with big data and cloud services.
Advantages of Using SQLite and SQLAlchemy in Python Projects
As engineering students, mastering SQLite and SQLAlchemy can provide you with several key advantages:
- Flexibility and Portability: SQLite’s lightweight and self-contained nature, combined with SQLAlchemy’s database-agnostic design, allows you to build applications that can be easily deployed and scaled across different environments.
- Productivity and Efficiency: The SQLAlchemy ORM abstracts away many low-level database details, enabling you to focus on writing application logic rather than dealing with database-specific code.
- Scalability and Performance: SQLite’s efficient design and SQLAlchemy’s optimization techniques can help you build applications that can handle growing data and traffic demands.
- Transferable Skills: Proficiency in SQLite and SQLAlchemy can be a valuable asset in your career, as these technologies are widely used in a variety of Python-based applications, from web development to data science.
- Versatility: The integration of SQLite and SQLAlchemy with big data frameworks and cloud services allows you to build applications that can seamlessly scale and adapt to changing requirements.
By mastering these technologies, you’ll be well-equipped to tackle a wide range of database-related challenges and build innovative, data-driven applications that can thrive in the ever-evolving world of Python development.
Trizula Mastery in Data Science is the perfect program for aspiring IT students looking to gain essential fundamentals in data science and industry-ready skills. This self-paced, flexible program equips participants with the necessary knowledge of contemporary technologies like data science, AI, ML, NLP, and SQLite, preparing them for future professional advancement. With an affordable cost and a commitment to empowering the current IT student community, this program is the ideal opportunity to become job-ready by the time you graduate. Click here to get started.
FAQs:
1. What is SQLAlchemy used for in Python?
SQLAlchemy is a SQL toolkit and Object-Relational Mapping (ORM) library for Python. It provides a full suite of well-known enterprise-level persistence patterns, designed for efficient and high-performing database access. SQLAlchemy allows developers to interact with the database using Python classes and objects instead of writing raw SQL queries.
2. What is Python SQLite3?
Python SQLite3 is a built-in module in Python that provides an interface for interacting with SQLite databases. SQLite is a self-contained, serverless, and zero-configuration database engine, which makes it easy to use for small to medium-sized applications. The SQLite3 module allows Python scripts to execute SQL commands directly on an SQLite database.
3. How to create a database in Python using SQLAlchemy?
To create a database using SQLAlchemy, you need to define a database URL and create an engine instance. Next, define your database models (tables) using Python classes and SQLAlchemy’s ORM features. Finally, use the create_all() method on the engine instance to create the database tables. Here’s a simple example:
Python code
from sqlalchemy import create_engine, Column, Integer, String, Base
engine = create_engine(‘sqlite:///example.db’)
Base = declarative_base()
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
name = Column(String)
Base.metadata.create_all(engine)
4. How to connect the SQLite3 database using Python?
To connect to an SQLite3 database using Python, you can use the SQLite3 module. First, import the module and use the connect() function to create a connection object. Next, create a cursor object using the cursor() method, which allows you to execute SQL commands. Here’s an example:
Python code
import sqlite3
connection = sqlite3.connect(‘example.db’)
cursor = connection.cursor()
cursor.execute(”’CREATE TABLE IF NOT EXISTS users (id INTEGER PRIMARY KEY, name TEXT)”’)
connection.commit()
connection.close()
5. What is the difference between SQLite and SQLAlchemy?
SQLite is a lightweight, self-contained database engine used to store data in a single file, while SQLAlchemy is a comprehensive SQL toolkit and ORM library for Python. SQLite is focused on providing a simple database solution, whereas SQLAlchemy offers tools for connecting to various databases, performing complex queries, and mapping database tables to Python objects. SQLAlchemy can be used with SQLite and other database systems, providing a higher level of abstraction and flexibility.


