
Target Audience: This Article on regression analysis is primarily aimed at students and professionals in data science, statistics, and related fields who want to gain a deep understanding of this powerful analytical technique.
Value Proposition: By covering the definition, importance, types, key concepts, applications, and considerations of regression analysis, this guide will equip readers with the knowledge and skills to effectively leverage regression for data analysis, prediction, and decision-making in a variety of real-world contexts.
Key Takeaways:
- Understand the fundamental principles of regression analysis, including the different types (linear, multiple, logistic, etc.) and their applications.
- Learn how to properly set up, interpret, and evaluate regression models, including addressing common challenges like overfitting and multicollinearity.
- Explore the ethical considerations and best practices in regression modeling, ensuring fairness and transparency in data-driven decision-making.
- Gain exposure to the latest tools and software for conducting regression analysis, and how to choose the most appropriate method for your specific needs.
- Discover how regression analysis compares to other analytical techniques and the unique advantages it offers for predictive modeling and inference.
Regression Analysis: Introduction to Modeling Relationships
Regression analysis is a powerful statistical technique used to model and analyze the relationship between a dependent variable and one or more independent variables. It is a fundamental tool in data analysis, machine learning, and predictive modeling. Regression analysis helps researchers, data scientists, and engineers understand how changes in the independent variables affect the dependent variable, and it allows them to make predictions based on the observed data.

Definition and Importance of Regression Analysis
Regression analysis is a statistical method used to estimate the relationship between a dependent variable and one or more independent variables. The goal is to find the best-fitting line or curve that represents the relationship between the variables. The resulting equation can be used to predict the value of the dependent variable based on the values of the independent variables.
Regression analysis is important because it allows researchers to:
- Understand the relationship between variables: Regression analysis helps identify the strength and direction of the relationship between variables, which is crucial for understanding the underlying mechanisms and making informed decisions.
- Make predictions: Once the relationship between variables is established, regression models can be used to predict the value of the dependent variable based on the values of the independent variables. This is particularly useful in fields such as finance, marketing, and engineering.
- Test hypotheses: Regression analysis can be used to test hypotheses about the relationship between variables, such as whether a particular independent variable has a significant effect on the dependent variable.
- Identify influential factors: Regression analysis can help identify the most influential factors that affect the dependent variable, which is valuable for optimizing processes and making targeted interventions.
Regression Analysis: Role in Data Analysis and Prediction
Regression analysis plays a crucial role in data analysis and prediction across various fields, including:
- Engineering: In engineering, regression analysis is used to model and optimize processes, predict equipment failures, and design experiments.
- Finance: In finance, regression analysis is used to model stock prices, predict market trends, and assess risk.
- Marketing: In marketing, regression analysis is used to predict customer behavior, optimize advertising campaigns, and segment markets.
- Medicine: In medicine, regression analysis is used to model disease progression, predict treatment outcomes, and identify risk factors for diseases.
- Social sciences: In social sciences, regression analysis is used to study the relationships between social phenomena, such as income and education, and to test theories about human behavior.
Regression Analysis is a fundamental tool for understanding relationships between variables, making predictions, and informing decision-making in a wide range of fields. By mastering regression analysis, engineering students can gain valuable skills for data analysis, problem-solving, and innovation.
Types of Regression Analysis
Regression analysis is a fundamental statistical tool used to understand the relationships between variables. It helps in predicting outcomes and making data-driven decisions. Here are some key types of regression analysis, explained with examples and visual aids to ensure clarity and practical insight.
1. Linear Regression
Definition: Linear regression is the simplest form of regression analysis. It models the relationship between a dependent variable (Y) and one independent variable (X) by fitting a linear equation to observed data.
Example: Suppose we want to predict a student’s final exam score based on the number of hours studied. The linear regression equation would look like:
Final Score=β0+β1×(Hours Studied)\text{Final Score} = \beta_0 + \beta_1 \times (\text{Hours Studied})Final Score=β0+β1×(Hours Studied)
Here, β0\beta_0β0 is the intercept, and β1\beta_1β1 is the slope of the line.
2. Multiple Regression
Definition: Multiple regression involves more than one independent variable to predict a single dependent variable. This method helps to understand the impact of multiple factors on an outcome.
Example: Predicting a student’s final exam score based on hours studied, attendance, and assignments completed.
Final Score=β0+β1×(Hours Studied)+β2×(Attendance)+β3×(Assignments Completed)\text{Final Score} = \beta_0 + \beta_1 \times (\text{Hours Studied}) + \beta_2 \times (\text{Attendance}) + \beta_3 \times (\text{Assignments Completed})Final Score=β0+β1×(Hours Studied)+β2×(Attendance)+β3×(Assignments Completed)
3. Polynomial Regression
Definition: Polynomial regression models the relationship between the dependent variable and the independent variable as an nth-degree polynomial. It captures non-linear relationships by transforming the original features.
Example: Predicting the trajectory of a projectile. A quadratic polynomial (degree 2) might look like:
y=β0+β1×x+β2×x2y = \beta_0 + \beta_1 \times x + \beta_2 \times x^2y=β0+β1×x+β2×x2
4. Logistic Regression
Definition: Logistic regression is used when the dependent variable is categorical, often binary (0 or 1). It predicts the probability of an event occurring.
Example: Predicting whether a student will pass (1) or fail (0) an exam based on hours studied.
logit(P)=ln(P1−P)=β0+β1×(Hours Studied)\text{logit}(P) = \ln \left( \frac{P}{1-P} \right) = \beta_0 + \beta_1 \times (\text{Hours Studied})logit(P)=ln(1−PP)=β0+β1×(Hours Studied)
Visual Representation:
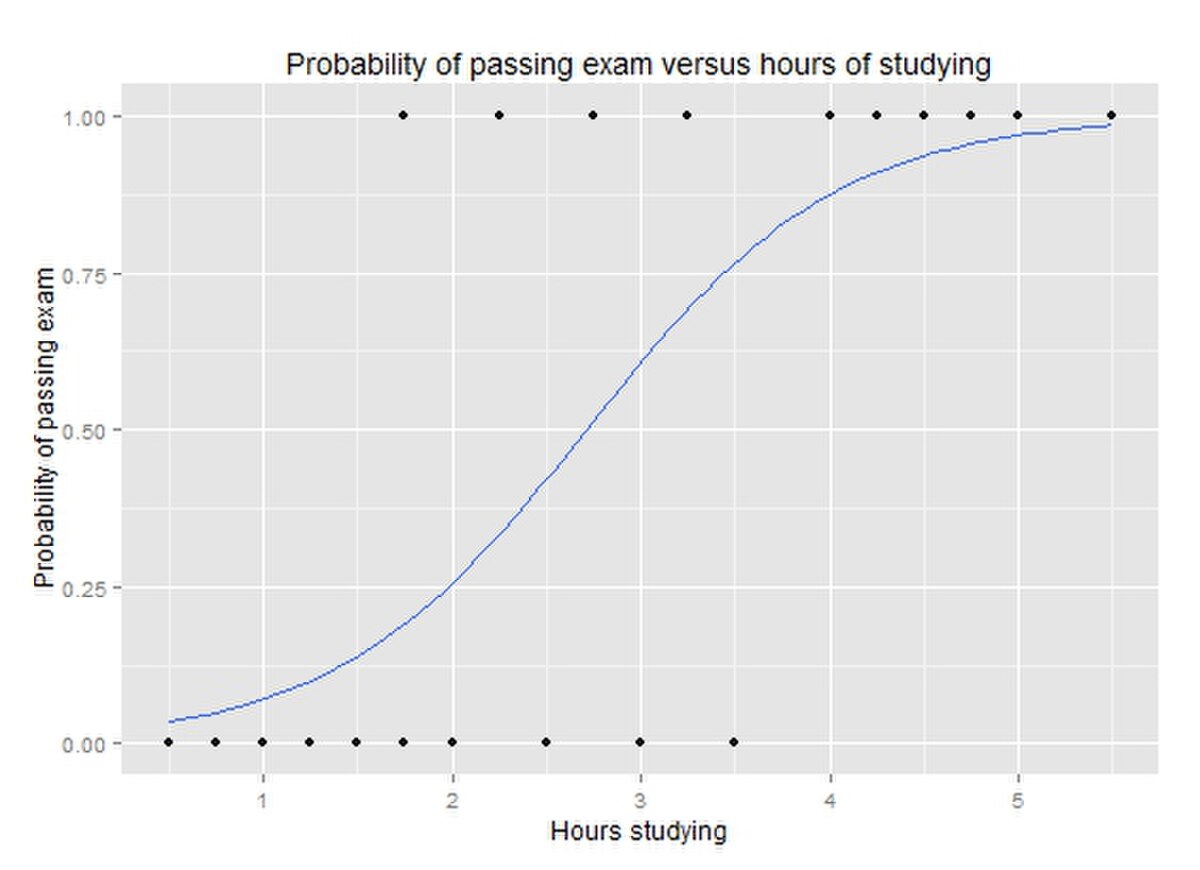
The S-shaped curve represents the probability of passing the exam as a function of hours studied.
5. Ridge Regression
Definition: Ridge regression is a technique used to analyze multiple regression data that suffer from multicollinearity. It adds a penalty equivalent to the sum of the squared values of the coefficients.
Example: In predicting house prices with multiple features, ridge regression helps to manage highly correlated predictors by adding a penalty to the regression coefficients.
Minimize∑i=1n(yi−β0−∑j=1pβjxij)2+λ∑j=1pβj2\text{Minimize} \quad \sum_{i=1}^{n} (y_i – \beta_0 – \sum_{j=1}^{p} \beta_j x_{ij})^2 + \lambda \sum_{j=1}^{p} \beta_j^2Minimize∑i=1n(yi−β0−∑j=1pβjxij)2+λ∑j=1pβj2
6. Lasso Regression
Definition: Lasso regression, or Least Absolute Shrinkage and Selection Operator, also adds a penalty to the regression coefficients but uses the absolute values. This can result in some coefficients being exactly zero, thus performing feature selection.
Example: In a model predicting sales, lasso regression can help identify which factors are most significant by shrinking less important feature coefficients to zero.
Minimize∑i=1n(yi−β0−∑j=1pβjxij)2+λ∑j=1p∣βj∣\text{Minimize} \quad \sum_{i=1}^{n} (y_i – \beta_0 – \sum_{j=1}^{p} \beta_j x_{ij})^2 + \lambda \sum_{j=1}^{p} |\beta_j|Minimize∑i=1n(yi−β0−∑j=1pβjxij)2+λ∑j=1p∣βj∣
7. ElasticNet Regression
Definition: ElasticNet regression combines the penalties of ridge and lasso regressions. It is useful when there are multiple correlated predictors.
Example: Predicting disease progression, where multiple biomarkers may be correlated, ElasticNet can provide a balanced approach by combining L1 and L2 penalties.
Minimize∑i=1n(yi−β0−∑j=1pβjxij)2+λ1∑j=1p∣βj∣+λ2∑j=1pβj2\text{Minimize} \quad \sum_{i=1}^{n} (y_i – \beta_0 – \sum_{j=1}^{p} \beta_j x_{ij})^2 + \lambda_1 \sum_{j=1}^{p} |\beta_j| + \lambda_2 \sum_{j=1}^{p} \beta_j^2Minimize∑i=1n(yi−β0−∑j=1pβjxij)2+λ1∑j=1p∣βj∣+λ2∑j=1pβj2
Understanding these types of regression analysis is crucial for making accurate predictions and informed decisions. By using real-world examples and visual aids, students can grasp the practical applications and importance of each type of regression analysis in data science and statistical modeling.
Key Concepts in Regression Analysis
Regression analysis is a powerful statistical method used to examine the relationship between two or more variables. This technique is widely used for prediction and forecasting, and its application spans various fields such as economics, biology, engineering, and social sciences.
Dependent and Independent Variables
In regression analysis, we primarily deal with two types of variables:
- Dependent Variable (Y): Also known as the response or outcome variable, it is the variable we are trying to predict or explain.
- Independent Variable (X): Also known as the predictor or explanatory variable, it is the variable we use to predict the dependent variable.
Example
Imagine you are studying the relationship between the number of hours studied and the scores on a test. Here:
- The test score is the dependent variable (Y).
- The number of hours studied is the independent variable (X).
Assumptions of Regression Analysis
For regression analysis to provide reliable results, several key assumptions need to be met:
- Linearity: The relationship between the dependent and independent variables should be linear.
- Independence: Observations should be independent of each other.
- Homoscedasticity: The variance of residuals (errors) should be constant across all levels of the independent variable.
- Normality: Residuals should be approximately normally distributed.
- No Multicollinearity: Independent variables should not be highly correlated with each other.
Residual Analysis
Residuals are the differences between the observed and predicted values of the dependent variable. Analyzing residuals helps in validating the assumptions of regression analysis and diagnosing potential issues.
- Residual Plot: A scatter plot of residuals on the vertical axis and the independent variable on the horizontal axis. This helps to check for homoscedasticity and linearity.
- Normal Q-Q Plot: A plot to check if residuals follow a normal distribution.
Example
Let’s consider a simple linear regression where we predict test scores based on hours studied.
Suppose the regression equation is: Score=50+5×Hours Studied\text{Score} = 50 + 5 \times \text{Hours Studied}Score=50+5×Hours Studied
If a student studied for 3 hours, the predicted score would be: Predicted Score=50+5×3=65\text{Predicted Score} = 50 + 5 \times 3 = 65Predicted Score=50+5×3=65
If the actual score was 70, the residual for this observation would be: Residual=70−65=5\text{Residual} = 70 – 65 = 5Residual=70−65=5
Practical Insight
- Application in Real Life: Regression analysis is used in various industries to make informed decisions. For instance, businesses use it to forecast sales, while economists use it to understand the impact of policy changes.
- Software Tools: Tools like R, Python (with libraries like statsmodels and sci-kit-learn), and even Excel can perform regression analysis.
- Interpretation: Understanding the coefficients of the regression equation is crucial. For example, in our test score prediction, the coefficient of 5 means that for each additional hour studied, the test score increases by 5 points.
Regression analysis is an essential tool for statistical analysis and prediction. By understanding the key concepts of dependent and independent variables, assumptions, and residual analysis, students can gain practical insights into how regression models work and how to apply them effectively in various scenarios.
Simple Linear Regression
Understanding the Simple Linear Regression Model
Simple linear regression is a statistical method that allows us to understand the relationship between two continuous variables. One variable is considered the predictor or independent variable, and the other is the response or dependent variable. The goal is to model the relationship between these variables by fitting a linear equation to observed data.
The simple linear regression model is represented by the equation: Y=β0+β1X+ϵY = \beta_0 + \beta_1X + \epsilonY=β0+β1X+ϵ where:
- YYY is the dependent variable.
- XXX is the independent variable.
- β0\beta_0β0 is the y-intercept (the value of YYY when XXX is 0).
- β1\beta_1β1 is the slope of the regression line (the change in YYY for a one-unit change in XXX).
- ϵ\epsilonϵ is the error term (the difference between the observed and predicted values of YYY).
Example: Imagine you want to study the relationship between the number of hours studied (independent variable, XXX) and the test scores (dependent variable, YYY) of students. By plotting the data points on a scatter plot and fitting a linear line, you can predict test scores based on the number of hours studied.
Estimating the Parameters (Slope and Intercept)
To estimate the parameters β0\beta_0β0 (intercept) and β1\beta_1β1 (slope), we use the method of least squares, which minimizes the sum of the squared differences between the observed and predicted values of YYY.
The formulas for the slope (β1\beta_1β1) and intercept (β0\beta_0β0) are: β1=∑(Xi−Xˉ)(Yi−Yˉ)∑(Xi−Xˉ)2\beta_1 = \frac{\sum (X_i – \bar{X})(Y_i – \bar{Y})}{\sum (X_i – \bar{X})^2}β1=∑(Xi−Xˉ)2∑(Xi−Xˉ)(Yi−Yˉ) β0=Yˉ−β1Xˉ\beta_0 = \bar{Y} – \beta_1\bar{X}β0=Yˉ−β1Xˉ where:
- XiX_iXi and YiY_iYi are the individual data points.
- Xˉ\bar{X}Xˉ and Yˉ\bar{Y}Yˉ are the means of the XXX and YYY variables, respectively.
Example Calculation: Suppose you have the following data on hours studied and test scores:
| Hours Studied (X) | Test Scores |
| 1 | 50 |
| 2 | 55 |
| 3 | 60 |
| 4 | 65 |
| 5 | 70 |
Calculate the mean of XXX and YYY:
Xˉ=1+2+3+4+55=3\bar{X} = \frac{1+2+3+4+5}{5} = 3Xˉ=51+2+3+4+5=3 Yˉ=50+55+60+65+705=60\bar{Y} = \frac{50+55+60+65+70}{5} = 60Yˉ=550+55+60+65+70=60
Calculate the slope (β1\beta_1β1): β1=(1−3)(50−60)+(2−3)(55−60)+(3−3)(60−60)+(4−3)(65−60)+(5−3)(70−60)(1−3)2+(2−3)2+(3−3)2+(4−3)2+(5−3)2\beta_1 = \frac{(1-3)(50-60) + (2-3)(55-60) + (3-3)(60-60) + (4-3)(65-60) + (5-3)(70-60)}{(1-3)^2 + (2-3)^2 + (3-3)^2 + (4-3)^2 + (5-3)^2}β1=(1−3)2+(2−3)2+(3−3)2+(4−3)2+(5−3)2(1−3)(50−60)+(2−3)(55−60)+(3−3)(60−60)+(4−3)(65−60)+(5−3)(70−60) β1=(−2)(−10)+(−1)(−5)+(0)(0)+(1)(5)+(2)(10)4+1+0+1+4\beta_1 = \frac{(-2)(-10) + (-1)(-5) + (0)(0) + (1)(5) + (2)(10)}{4 + 1 + 0 + 1 + 4}β1=4+1+0+1+4(−2)(−10)+(−1)(−5)+(0)(0)+(1)(5)+(2)(10) β1=20+5+0+5+2010=5\beta_1 = \frac{20 + 5 + 0 + 5 + 20}{10} = 5β1=1020+5+0+5+20=5
Calculate the intercept (β0\beta_0β0): β0=Yˉ−β1Xˉ\beta_0 = \bar{Y} – \beta_1\bar{X}β0=Yˉ−β1Xˉ β0=60−5×3=45\beta_0 = 60 – 5 \times 3 = 45β0=60−5×3=45
Thus, the estimated regression line is: Y=45+5XY = 45 + 5XY=45+5X
Interpreting the Regression Coefficients
The regression coefficients β0\beta_0β0 (intercept) and β1\beta_1β1 (slope) provide valuable insights into the relationship between the variables.
- Intercept (β0\beta_0β0): This is the predicted value of YYY when XXX is 0. In our example, the intercept is 45, which means that if a student studies for 0 hours, the predicted test score is 45.
- Slope (β1\beta_1β1): This represents the change in YYY for a one-unit change in XXX. In our example, the slope is 5, indicating that for each additional hour studied, the test score increases by 5 points.
Practical Insight: Understanding these coefficients can help in making informed decisions. For instance, educators can use this information to set realistic expectations and create effective study plans. Students can understand the impact of their study habits on their performance.
Simple linear regression is a foundational tool in statistics that helps us understand and quantify relationships between variables. By estimating the parameters and interpreting the regression coefficients, we can make informed predictions and gain practical insights into various real-world scenarios. Whether in education, business, or science, mastering simple linear regression provides a valuable skill set for data-driven decision-making.
Multiple Linear Regression
Multiple Linear Regression (MLR) is an extension of simple linear regression that uses two or more explanatory variables to predict the outcome of a response variable. This statistical technique is used to understand the relationship between several independent variables and a dependent variable.
Equation:
Y=β0+β1X1+β2X2+…+βnXn+ϵY = \beta_0 + \beta_1X_1 + \beta_2X_2 + \ldots + \beta_nX_n + \epsilonY=β0+β1X1+β2X2+…+βnXn+ϵ
where:
- YYY is the dependent variable.
- β0\beta_0β0 is the intercept.
- β1,β2,…,βn\beta_1, \beta_2, \ldots, \beta_nβ1,β2,…,βn are the coefficients of the independent variables X1,X2,…,XnX_1, X_2, \ldots, X_nX1,X2,…,Xn.
- ϵ\epsilonϵ is the error term.
Example:
Suppose we want to predict a student’s final exam score based on hours studied (X1), number of classes attended (X2), and previous test scores (X3).
Score=β0+β1(Hours Studied)+β2(Classes Attended)+β3(Previous Scores)+ϵ\text{Score} = \beta_0 + \beta_1(\text{Hours Studied}) + \beta_2(\text{Classes Attended}) + \beta_3(\text{Previous Scores}) + \epsilonScore=β0+β1(Hours Studied)+β2(Classes Attended)+β3(Previous Scores)+ϵ

Extending to Multiple Predictors
Multiple linear regression (MLR) is an extension of simple linear regression that uses multiple independent variables (predictors) to predict a dependent variable (response). This approach is valuable when you need to consider the influence of several factors on the outcome.
Example: Consider predicting a student’s final exam score based on their hours of study, attendance rate, and number of practice tests taken. The MLR model would look like:
Final Score=β0+β1⋅Hours of Study+β2⋅Attendance Rate+β3⋅Practice Tests+ϵ\text{Final Score} = \beta_0 + \beta_1 \cdot \text{Hours of Study} + \beta_2 \cdot \text{Attendance Rate} + \beta_3 \cdot \text{Practice Tests} + \epsilonFinal Score=β0+β1⋅Hours of Study+β2⋅Attendance Rate+β3⋅Practice Tests+ϵ
Here, β0\beta_0β0 is the intercept, β1,β2,β3\beta_1, \beta_2, \beta_3β1,β2,β3 are the coefficients for each predictor, and ϵ\epsilonϵ is the error term.
Assumptions and Interpretation
Multiple linear regression relies on several key assumptions:
- Linearity: The relationship between each predictor and the response is linear.
- Independence: Observations are independent of each other.
- Homoscedasticity: The variance of error terms is constant across all levels of the predictors.
- Normality: The error terms are normally distributed.
- No Multicollinearity: Predictors are not highly correlated with each other.
Example Interpretation: If β1=5\beta_1 = 5β1=5, it means that for each additional hour of study, the final exam score increases by 5 points, assuming other variables are held constant.
Model Selection Techniques
Choosing the right predictors for your model is crucial. Here are two common techniques:
- Backward Elimination:
- Start with all predictors.
- Remove the least significant predictor (highest p-value greater than a significance level, typically 0.05).
- Refit the model and repeat until all remaining predictors are significant.
Example:
- Initial model: Final Score∼Hours of Study+Attendance Rate+Practice Tests+Group Study Hours\text{Final Score} \sim \text{Hours of Study} + \text{Attendance Rate} + \text{Practice Tests} + \text{Group Study Hours}Final Score∼Hours of Study+Attendance Rate+Practice Tests+Group Study Hours
- Group Study Hours has a p-value of 0.6 (not significant).
- Remove Group Study Hours and refit the model.
- Forward Selection:
- Start with no predictors.
- Add the most significant predictor (lowest p-value less than 0.05).
- Add the next significant predictor and repeat until no significant predictors are left to add.
Example:
- Start with none.
- Add Hours of Study (most significant predictor).
- Add Attendance Rate, then Practice Tests.
Practical Insight
Implementing Multiple Linear Regression in Python
To provide practical insight, let’s implement MLR using Python and the statsmodels library.
Python Code Example:
import pandas as pd
import statsmodels.api as sm
# Sample data
data = {
‘Hours of Study’: [10, 20, 30, 40, 50],
‘Attendance Rate’: [0.9, 0.8, 0.85, 0.95, 0.7],
‘Practice Tests’: [2, 3, 4, 3, 5],
‘Final Score’: [80, 85, 88, 90, 75]
}
df = pd.DataFrame(data)
# Define predictors and response
X = df[[‘Hours of Study’, ‘Attendance Rate’, ‘Practice Tests’]]
y = df[‘Final Score’]
# Add a constant to the model (intercept)
X = sm.add_constant(X)
# Fit the model
model = sm.OLS(y, X).fit()
# Print model summary
print(model.summary())
This code fits a multiple linear regression model to the data and prints a summary, including coefficients, p-values, and R-squared values, which indicates the model’s goodness of fit.
Understanding multiple linear regression and its techniques is fundamental for data analysis. By grasping the assumptions, interpretations, and model selection methods, students can effectively build and refine predictive models. Practical implementation using tools like Python ensures they are well-prepared for real-world data challenges.
Non-Linear Regression
Non-linear regression is a form of regression analysis in which data is modeled by a function that is a non-linear combination of the model parameters and depends on one or more independent variables. Non-linear regression provides a powerful tool for modeling complex relationships that cannot be adequately captured by linear models. This article will delve into the essentials of non-linear regression, including modeling non-linear relationships, examples and applications, and various curve-fitting methods.
Modeling Non-Linear Relationships
Understanding Non-Linear Relationships
In many real-world situations, the relationship between the independent and dependent variables is not linear. For example, the growth of populations, the spread of diseases, and the response of materials to stress often follow non-linear patterns. Non-linear regression allows us to model these relationships more accurately.
Key Concepts
- Non-linear Function: A function in which the change in the dependent variable is not proportional to the change in the independent variable(s). Examples include exponential, logarithmic, and polynomial functions.
- Residuals: The differences between observed values and the values predicted by the model. In non-linear regression, minimizing these residuals often involves iterative algorithms.
Practical Insight
Unlike linear regression, where we can directly solve for coefficients, non-linear regression typically requires iterative optimization techniques. Common methods include the Newton-Raphson method, the Gauss-Newton method, and the Levenberg-Marquardt algorithm.
Example
Consider a scenario where we want to model the growth of bacteria over time. A common model is the logistic growth model, which is non-linear:
y=K1+e−(r(t−t0))y = \frac{K}{1 + e^{-(r(t-t_0))}}y=1+e−(r(t−t0))K
where:
- yyy is the population size,
- KKK is the carrying capacity,
- rrr is the growth rate,
- ttt is time,
- t0t_0t0 is the time at the inflection point.
Examples and Applications
Non-linear regression is widely used in various fields due to its flexibility in modeling complex relationships. Here are some examples and applications:
Example 1: Pharmacokinetics
In pharmacokinetics, the concentration of a drug in the bloodstream often follows a non-linear pattern. The Michaelis-Menten model, used to describe enzyme kinetics, is a well-known non-linear model:
v=Vmax⋅[S]Km+[S]v = \frac{V_{max} \cdot [S]}{K_m + [S]}v=Km+[S]Vmax⋅[S]
where:
- vvv is the rate of reaction,
- VmaxV_{max}Vmax is the maximum rate,
- [S][S][S] is the substrate concentration,
- KmK_mKm is the Michaelis constant.

Example 2: Economics
In economics, non-linear regression can be used to model the relationship between production inputs and outputs. The Cobb-Douglas production function is a popular example:
Y=A⋅Lα⋅KβY = A \cdot L^{\alpha} \cdot K^{\beta}Y=A⋅Lα⋅Kβ
where:
- YYY is the total production,
- AAA is total factor productivity,
- LLL is labor input,
- KKK is capital input,
- α\alphaα and β\betaβ are output elasticities of labor and capital, respectively.
Curve Fitting Methods
Polynomial Regression
Polynomial regression fits a polynomial equation to the data. It is useful for modeling curvilinear relationships.
y=β0+β1x+β2×2+⋯+βnxny = \beta_0 + \beta_1 x + \beta_2 x^2 + \cdots + \beta_n x^ny=β0+β1x+β2x2+⋯+βnxn
Exponential Regression
Exponential regression models relationships where the rate of change increases or decreases exponentially.
y=α⋅eβxy = \alpha \cdot e^{\beta x}y=α⋅eβx
Logistic Regression
Logistic regression, commonly used for binary classification problems, can also be adapted for non-linear regression by fitting a logistic function to the data.
y=11+e−(β0+β1x)y = \frac{1}{1 + e^{-(\beta_0 + \beta_1 x)}}y=1+e−(β0+β1x)1
Spline Regression
Spline regression involves fitting piecewise polynomials to the data. It is particularly useful for capturing local variations in the data.
Practical Tips for Non-Linear Regression
- Understand the Data: Before applying non-linear regression, visualize the data to understand the underlying relationship.
- Choose the Right Model: Select a model that best fits the data. Consider the theoretical basis for the chosen model.
- Iterative Optimization: Use iterative methods for parameter estimation. Common algorithms include the Levenberg-Marquardt and Gauss-Newton methods.
- Evaluate the Fit: Assess the model fit using residual analysis and goodness-of-fit metrics such as R-squared and RMSE.
- Avoid Overfitting: Be cautious of overfitting, especially when using high-degree polynomials or complex models. Cross-validation can help mitigate this risk.
Non-linear regression is a versatile tool for modeling complex relationships that linear models cannot adequately capture. By understanding and applying non-linear regression techniques, you can gain deeper insights into your data and make more accurate predictions. Whether you are analyzing biological growth patterns, economic production functions, or pharmacokinetic properties, non-linear regression provides the flexibility and power needed to tackle a wide range of real-world problems.
Logistic Regression
Logistic regression is a powerful statistical method used for classification problems where the outcome is a categorical variable. It is particularly useful when the dependent variable is binary (two possible outcomes) or multinomial (more than two possible outcomes). Unlike linear regression, logistic regression models the probability of a particular outcome using a logistic function, which ensures that the predicted probabilities are between 0 and 1.
Binary Logistic Regression
Definition and Basics: Binary logistic regression is used when the dependent variable has two categories, such as success/failure, yes/no, or 0/1. The logistic function (or sigmoid function) transforms the linear combination of the input features into a probability value between 0 and 1.
The logistic function is given by:
P(Y=1∣X)=11+e−(β0+β1X1+β2X2+…+βnXn)P(Y=1|X) = \frac{1}{1 + e^{-(\beta_0 + \beta_1X_1 + \beta_2X_2 + \ldots + \beta_nX_n)}}P(Y=1∣X)=1+e−(β0+β1X1+β2X2+…+βnXn)1
Here, P(Y=1∣X)P(Y=1|X)P(Y=1∣X) is the probability of the dependent variable being 1 given the input features XXX, and β0,β1,…,βn\beta_0, \beta_1, \ldots, \beta_nβ0,β1,…,βn are the coefficients to be estimated.
Example: Predicting Loan Approval Imagine you are working at a bank and want to predict whether a loan application will be approved or not based on applicant features such as credit score, income, and loan amount.
Python code
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, auc
# Sample data
data = {
‘Credit_Score’: [700, 650, 600, 720, 680, 750, 640, 690, 710, 680],
‘Income’: [120000, 100000, 80000, 130000, 115000, 140000, 95000, 125000, 110000, 105000],
‘Loan_Amount’: [200000, 150000, 100000, 250000, 180000, 270000, 160000, 230000, 190000, 170000],
‘Approved’: [1, 0, 0, 1, 1, 1, 0, 1, 1, 0]
}
df = pd.DataFrame(data)
# Features and target
X = df[[‘Credit_Score’, ‘Income’, ‘Loan_Amount’]]
y = df[‘Approved’]
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Logistic Regression model
model = LogisticRegression()
model.fit(X_train, y_train)
# Predictions
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1]
# Evaluation
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
# ROC Curve
fpr, tpr, thresholds = roc_curve(y_test, y_prob)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color=’darkorange’, lw=2, label=f’ROC curve (area = {roc_auc:.2f})’)
plt.plot([0, 1], [0, 1], color=’navy’, lw=2, linestyle=’–‘)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel(‘False Positive Rate’)
plt.ylabel(‘True Positive Rate’)
plt.title(‘Receiver Operating Characteristic’)
plt.legend(loc=’lower right’)
plt.show()
Interpretation:
- The coefficients indicate the relationship between each feature and the probability of loan approval.
- The ROC curve and AUC value provide insights into the model’s performance.

Multinomial Logistic Regression
Definition and Basics: Multinomial logistic regression is used when the dependent variable has more than two categories. The model is an extension of binary logistic regression and uses the softmax function to predict the probabilities of different outcomes.
The softmax function is given by:
P(Y=j∣X)=eβ0j+β1jX1+β2jX2+…+βnjXn∑k=1Keβ0k+β1kX1+β2kX2+…+βnkXnP(Y=j|X) = \frac{e^{\beta_{0j} + \beta_{1j}X_1 + \beta_{2j}X_2 + \ldots + \beta_{nj}X_n}}{\sum_{k=1}^{K} e^{\beta_{0k} + \beta_{1k}X_1 + \beta_{2k}X_2 + \ldots + \beta_{nk}X_n}}P(Y=j∣X)=∑k=1Keβ0k+β1kX1+β2kX2+…+βnkXneβ0j+β1jX1+β2jX2+…+βnjXn
Here, P(Y=j∣X)P(Y=j|X)P(Y=j∣X) is the probability of the dependent variable being in category jjj given the input features XXX, and β0j,β1j,…,βnj\beta_{0j}, \beta_{1j}, \ldots, \beta_{nj}β0j,β1j,…,βnj are the coefficients for category jjj.
Example: Predicting Customer Purchase Behavior Consider a retail store that wants to predict the type of product (electronics, clothing, groceries) a customer is likely to purchase based on features such as age, income, and previous purchase history.
Python code
# Sample data
data = {
‘Age’: [25, 45, 35, 50, 23, 34, 67, 29, 48, 51],
‘Income’: [40000, 85000, 60000, 120000, 32000, 54000, 75000, 39000, 97000, 110000],
‘Previous_Purchase’: [0, 1, 0, 1, 0, 0, 1, 0, 1, 1],
‘Product_Type’: [‘Electronics’, ‘Clothing’, ‘Groceries’, ‘Clothing’, ‘Electronics’, ‘Groceries’, ‘Clothing’, ‘Electronics’, ‘Groceries’, ‘Clothing’]
}
df = pd.DataFrame(data)
# Features and target
X = df[[‘Age’, ‘Income’, ‘Previous_Purchase’]]
y = df[‘Product_Type’]
# Encode target variable
y_encoded = pd.get_dummies(y)
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.3, random_state=42)
# Multinomial Logistic Regression model
model = LogisticRegression(multi_class=’multinomial’, solver=’lbfgs’)
model.fit(X_train, y_train)
# Predictions
y_pred = model.predict(X_test)
# Evaluation
print(confusion_matrix(y_test.values.argmax(axis=1), y_pred.argmax(axis=1)))
print(classification_report(y_test.values.argmax(axis=1), y_pred.argmax(axis=1)))
Interpretation:
- The confusion matrix and classification report help evaluate the model’s performance in predicting each category.
- The coefficients indicate the relationship between each feature and the probability of each product type being purchased.
Applications in Classification Problems
Medical Diagnosis: Logistic regression is widely used in medical fields to predict the presence or absence of diseases based on patient data. For example, predicting the likelihood of heart disease based on features such as age, cholesterol levels, and blood pressure.
Marketing Campaigns: Marketers use logistic regression to predict whether a customer will respond to a campaign (binary outcome) or to categorize customers into segments for targeted marketing (multinomial outcome).
Credit Scoring: Banks and financial institutions use logistic regression to assess the creditworthiness of applicants by predicting the probability of default.
Customer Churn: Businesses use logistic regression to predict whether a customer is likely to churn based on their interaction history, usage patterns, and demographic information.
Logistic regression is a versatile and powerful tool for classification problems. Understanding binary and multinomial logistic regression, along with their practical applications, equips students with essential skills for data analysis and predictive modeling. By leveraging logistic regression, one can make informed decisions across various domains, from finance to healthcare and beyond.
Regularization Techniques
In regression analysis, overfitting is a common problem where the model performs well on the training data but poorly on unseen data. Regularization techniques help mitigate overfitting by adding a penalty term to the loss function, which discourages overly complex models. Here, we will explore three popular regularization techniques: Ridge regression (L2 regularization), Lasso regression (L1 regularization), and ElasticNet regression. We’ll provide in-depth explanations, practical insights, and visual representations to help students grasp these concepts effectively.
Ridge Regression (L2 Regularization)
Concept: Ridge regression adds a penalty equal to the square of the magnitude of coefficients to the loss function. This shrinks the coefficients, effectively reducing model complexity and multicollinearity.
Mathematical Formulation: The Ridge regression objective function is: Minimize{∑i=1n(yi−y^i)2+λ∑j=1pβj2}\text{Minimize} \left\{ \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \lambda \sum_{j=1}^{p} \beta_j^2 \right\}Minimize{∑i=1n(yi−y^i)2+λ∑j=1pβj2} where:
- yiy_iyi is the actual value.
- y^i\hat{y}_iy^i is the predicted value.
- βj\beta_jβj are the coefficients.
- λ\lambdaλ is the regularization parameter.
Example: Let’s consider a dataset predicting house prices based on features like size, number of rooms, and location.
Python code
import numpy as np
from sklearn.linear_model import Ridge
import matplotlib.pyplot as plt
# Generating synthetic data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
# Ridge regression
ridge_reg = Ridge(alpha=1)
ridge_reg.fit(X, y)
y_pred = ridge_reg.predict(X)
# Plotting
plt.scatter(X, y, color=’blue’, label=’Actual’)
plt.plot(X, y_pred, color=’red’, label=’Ridge Prediction’)
plt.xlabel(‘Feature’)
plt.ylabel(‘Target’)
plt.title(‘Ridge Regression’)
plt.legend()
plt.show()
Practical Insight: Ridge regression works well when all predictors influence the target variable and tend to have coefficients distributed more evenly. The regularization parameter λ\lambdaλ controls the amount of shrinkage; larger values lead to greater shrinkage.

Lasso Regression (L1 Regularization)
Concept: Lasso regression adds a penalty equal to the absolute value of the magnitude of coefficients to the loss function. This can shrink some coefficients to zero, effectively performing feature selection.
Mathematical Formulation: The Lasso regression objective function is: Minimize{∑i=1n(yi−y^i)2+λ∑j=1p∣βj∣}\text{Minimize} \left\{ \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \lambda \sum_{j=1}^{p} |\beta_j| \right\}Minimize{∑i=1n(yi−y^i)2+λ∑j=1p∣βj∣}
Example: Let’s use the same dataset as in the Ridge regression example.
Python code
from sklearn.linear_model import Lasso
# Lasso regression
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X, y)
y_pred = lasso_reg.predict(X)
# Plotting
plt.scatter(X, y, color=’blue’, label=’Actual’)
plt.plot(X, y_pred, color=’red’, label=’Lasso Prediction’)
plt.xlabel(‘Feature’)
plt.ylabel(‘Target’)
plt.title(‘Lasso Regression’)
plt.legend()
plt.show()
Practical Insight: Lasso regression is useful when we have a large number of features and expect only a few of them to be important. By shrinking some coefficients to zero, it effectively reduces the dimensionality of the model, making it easier to interpret.
ElasticNet Regression
Concept: ElasticNet regression combines both L1 and L2 penalties. It is particularly useful when there are multiple correlated features. ElasticNet can retain the benefits of both Ridge and Lasso regression.
Mathematical Formulation: The ElasticNet regression objective function is: Minimize{∑i=1n(yi−y^i)2+λ1∑j=1p∣βj∣+λ2∑j=1pβj2}\text{Minimize} \left\{ \sum_{i=1}^{n} (y_i – \hat{y}_i)^2 + \lambda_1 \sum_{j=1}^{p} |\beta_j| + \lambda_2 \sum_{j=1}^{p} \beta_j^2 \right\}Minimize{∑i=1n(yi−y^i)2+λ1∑j=1p∣βj∣+λ2∑j=1pβj2}
Example: Using the same dataset again.
Python code
from sklearn.linear_model import ElasticNet
# ElasticNet regression
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X, y)
y_pred = elastic_net.predict(X)
# Plotting
plt.scatter(X, y, color=’blue’, label=’Actual’)
plt.plot(X, y_pred, color=’red’, label=’ElasticNet Prediction’)
plt.xlabel(‘Feature’)
plt.ylabel(‘Target’)
plt.title(‘ElasticNet Regression’)
plt.legend()
plt.show()
Practical Insight: ElasticNet is a versatile regularization technique, especially useful when dealing with complex datasets where predictors are correlated. The parameters λ1\lambda_1λ1 and λ2\lambda_2λ2 allow tuning the balance between L1 and L2 regularization, providing a flexible approach to control overfitting and feature selection.
Regularization techniques are crucial tools in regression analysis to prevent overfitting and improve model generalization. Ridge regression shrinks coefficients uniformly, Lasso regression performs feature selection by shrinking some coefficients to zero, and ElasticNet combines both approaches for more flexibility. Understanding these techniques, along with practical examples and visualizations, equips students with valuable skills to handle complex datasets effectively.
Model Evaluation in Regression Analysis
Evaluation of regression models is crucial to assess their performance, reliability, and suitability for real-world applications. This process involves several key components that provide insights into the model’s effectiveness and potential areas for improvement.
Measures of Goodness of Fit (R-squared, Adjusted R-squared)
R-squared (R²): R-squared is a statistical measure that represents the proportion of the variance for a dependent variable that’s explained by an independent variable or variables in a regression model. It ranges from 0 to 1, where 0 indicates that the model does not explain any variability in the response variable, and 1 indicates that the model explains all the variability.
Example: Consider a simple linear regression model predicting house prices based on area. An R-squared value of 0.75 means that 75% of the variance in house prices can be explained by the variance in the house area.
Adjusted R-squared: Adjusted R-squared adjusts the R-squared value for the number of predictors in the model. It penalizes the addition of unnecessary variables that do not improve the model significantly, providing a more reliable measure of goodness of fit for models with multiple predictors.
Example: In a multiple linear regression model with several predictors (e.g., area, location, age), the adjusted R-squared will be lower than the R-squared if the additional predictors do not contribute sufficiently to explaining the variance in the dependent variable.

Residual Analysis (Homoscedasticity, Normality)
Homoscedasticity: Homoscedasticity refers to the assumption that the variance of errors or residuals is constant across all levels of the independent variables. In regression analysis, it indicates that the residuals are evenly spread around the regression line, implying that the model’s predictions are equally accurate across the range of predictor values.
Example: A scatter plot of residuals against predicted values can show whether the spread of residuals remains consistent as predicted values change. Deviations from a consistent spread indicate heteroscedasticity.
Normality: The normality of residuals assumes that the residuals follow a normal distribution. It’s crucial because many statistical tests and intervals in regression analysis rely on this assumption. Deviations from normality might suggest issues like outliers or transformation needs.
Example: A histogram or Q-Q plot of residuals can visually inspect whether the residuals approximate a normal distribution. Skewness or heavy tails indicate a departure from normality.
Cross-Validation Techniques
Cross-validation techniques assess the performance and generalization ability of a regression model by training and testing it on different subsets of the data. This helps to estimate how the model will perform on new data not used in training.
Example: K-fold cross-validation divides the data into k subsets (folds). The model is trained on k-1 folds and tested on the remaining folds. This process is repeated k times, and the average performance metric (e.g., mean squared error) across all folds is used to evaluate the model.
These components together provide a comprehensive framework for evaluating regression models, ensuring both statistical rigor and practical applicability in real-world scenarios.
Applications of Regression Analysis
Regression analysis finds widespread applications across various fields due to its ability to model relationships between variables. Here are some key application areas:
1. Business
- Sales Forecasting: Companies use regression to predict future sales based on historical data, economic indicators, and market trends.
- Marketing Effectiveness: Regression helps assess the impact of marketing campaigns on sales or brand perception.
- Financial Analysis: Regression models are used in risk assessment, portfolio management, and credit scoring.
2. Healthcare
- Medical Research: Regression helps analyze the relationship between variables like patient characteristics and treatment outcomes.
- Epidemiology: Predicting disease prevalence based on factors like demographics, lifestyle, and environmental conditions.
- Healthcare Costs: Predicting healthcare costs based on patient demographics and medical history.
3. Social Sciences
- Education: Regression helps identify factors influencing academic performance, such as student demographics, teaching methods, and socioeconomic status.
- Psychology: Analyzing factors affecting mental health outcomes or behavior patterns.
- Sociology: Understanding social phenomena like crime rates, voting behavior, or income inequality.
Real-World Examples and Case Studies
1. Business Example:
- Case Study: A retail chain uses regression to analyze the impact of store location, demographics, and competitor presence on sales. By modeling these factors, they optimize new store placements to maximize profitability.
2. Healthcare Example:
- Case Study: A hospital uses regression to predict patient readmission rates based on factors such as age, previous medical history, and post-discharge care quality. This helps in resource allocation and improving patient outcomes.
3. Social Sciences Example:
- Case Study: Researchers use regression to study the impact of social programs on poverty levels in different regions. By analyzing data on program implementation, demographics, and economic indicators, they assess effectiveness and recommend policy changes.
Challenges and Considerations
1. Overfitting and Underfitting:
- Overfitting: Occurs when a model learns noise or random fluctuations in the training data, leading to poor performance on new data.
- Underfitting: Occurs when a model is too simple to capture the underlying relationships, resulting in low predictive power.
2. Multicollinearity:
- Definition: High correlation between predictor variables, which can lead to unstable estimates of regression coefficients.
- Impact: It becomes challenging to interpret the individual effects of predictors when they are highly correlated.
Interpreting Complex Models
1. Model Interpretation:
- Coefficient Interpretation: Understanding how changes in predictor variables relate to changes in the response variable.
- Model Diagnostics: Assessing model fit using measures like R-squared, residual analysis, and hypothesis testing.
2. Visualizing Relationships:
- Partial Dependence Plots: Showing the relationship between a predictor and the response variable while accounting for the average effect of other predictors.
- Interaction Effects: Visualizing how the relationship between predictors and the response variable changes based on the values of other predictors.
By exploring these aspects of regression analysis through real-world examples and addressing common challenges, students can gain a comprehensive understanding of its practical application and significance across different domains.
Tools and Software for Regression Analysis
Overview of Statistical Software Tools
Statistical software tools play a crucial role in regression analysis, offering a wide range of features and capabilities that empower analysts to explore relationships between variables, make predictions, and derive meaningful insights from data. Here’s an overview of some popular tools:
1. R:
- Features: R is an open-source statistical computing environment known for its powerful capabilities in regression analysis. It provides numerous packages like lm for linear regression, glm for generalized linear models including logistic regression, and caret for model training and evaluation.
- Capabilities: R excels in data manipulation, visualization (using ggplot2), and advanced statistical modeling. It supports various regression techniques, making it versatile for both basic and complex analyses.
2. Python:
- Features: Python, with libraries like numpy, pandas, and statsmodels, offers robust tools for data handling, manipulation, and statistical modeling. scikit-learn provides implementations for various regression algorithms.
- Capabilities: Python is favored for its ease of use and integration with other data science libraries. It supports linear regression (statsmodels), polynomial regression, and more sophisticated techniques like ridge and lasso regression.
3. SAS (Statistical Analysis System):
- Features: SAS is a comprehensive software suite for advanced analytics and business intelligence. It includes procedures (PROC REG) specifically designed for regression analysis, along with graphical capabilities for visualization.
- Capabilities: SAS is widely used in industries requiring rigorous statistical analysis and has extensive support for regression diagnostics, model selection criteria, and handling large datasets efficiently.
4. SPSS (Statistical Package for the Social Sciences):
- Features: SPSS is known for its user-friendly interface and robust statistical capabilities. It provides a range of regression procedures (REGRESSION, LOGISTIC) with options for variable selection, model comparison, and diagnostic tools.
- Capabilities: SPSS is popular in social sciences and market research for its ability to handle complex regression models and generate comprehensive reports with graphical outputs.
Features and Capabilities for Performing Regression Analysis
Regression analysis involves fitting mathematical models to data to understand relationships between variables. Here’s a detailed look at the features and capabilities offered by these tools:
1. Data Handling and Preparation:
- Example: In Python, using pandas to load and preprocess data before regression analysis. Visualizing relationships with scatter plots helps in initial exploration.
2. Model Building and Evaluation:
- Example: Using R to build a linear regression model (lm) to predict housing prices based on square footage and number of bedrooms. Evaluating model performance using R-squared and residual plots.
3. Advanced Techniques and Algorithms:
- Example: Implementing ridge regression in Python’s sci-kit-learn to handle multicollinearity issues in the dataset. Visualizing the impact of regularization parameters on coefficient estimates.
4. Interpretation and Reporting:
- Example: Using SAS to interpret logistic regression results for predicting customer churn. Generating ROC curves to evaluate model accuracy and choosing optimal thresholds.
Choosing the right statistical software tool depends on specific needs, data characteristics, and the complexity of regression analysis tasks.
Each tool offers unique advantages in terms of functionality, ease of use, and community support, empowering analysts to derive actionable insights from data effectively.
By leveraging these tools’ features and capabilities, students and professionals alike can enhance their understanding and application of regression analysis in real-world scenarios.
Ethical Considerations in Regression Analysis
Ethical issues play a crucial role in data-driven fields like regression analysis, where decisions can impact individuals and society. Key considerations include:
- Privacy and Confidentiality: Ensuring that data collection respects individuals’ privacy rights and that sensitive information is handled confidentially.
Example: In healthcare regression models predicting patient outcomes, ensuring that patient data is anonymized and securely stored. - Bias and Fairness: Mitigating biases in data and algorithms to prevent discrimination and ensure fairness in predictions.
Example: In loan approval models, ensuring that factors like race or gender do not influence decisions unfairly. - Transparency and Accountability: Making models understandable and ensuring that stakeholders can interpret results and understand how decisions are made.
Example: Providing clear documentation and explanations of model inputs and outputs. - Informed Consent: Obtaining informed consent from individuals whose data is used in analysis, particularly in sensitive or identifiable data contexts.
Example: Research studies require participants to consent to their data being used for analysis purposes.
Comparison with Other Analytical Methods
Regression analysis is powerful but distinct from other predictive modeling techniques. Contrasting it helps understand its unique advantages and limitations:
- Advantages of Regression Analysis:
- Interpretability: Easily interpretable coefficients help understand the relationship between predictors and outcomes.
- Versatility: Works well with continuous and categorical predictors.
- Established Framework: Well-established theory and methods make it widely applicable.
- Limitations of Regression Analysis:
- Assumptions: Requires assumptions about linearity, independence, and normality.
- Overfitting: Prone to overfitting with many predictors or complex models.
- Non-linear Relationships: Limited in capturing complex, non-linear relationships without transformations or extensions.
Summary of Key Concepts in Regression Analysis
Understanding key concepts is essential for mastering regression analysis:
- Types of Regression:
- Linear Regression: Predicts a continuous outcome based on linear relationships.
- Logistic Regression: Predicts binary outcomes using a logistic function.
- Non-linear Regression: Models non-linear relationships using polynomial terms or other functions.
- Model Evaluation:
- Goodness of Fit: Measures like R-squared quantify how well the model fits the data.
- Residual Analysis: Checks assumptions and model performance using residuals.
- Cross-validation: Validates model performance on unseen data to prevent overfitting.
Future Trends and Advancements in Regression Analysis
The field of regression analysis continues to evolve with advancements in technology and methodology:
- AI and Automation: Integration of machine learning techniques to automate model building and enhance predictive accuracy.
Example: Using automated feature selection methods to improve model robustness. - Big Data and Cloud Technologies: Handling large datasets efficiently through cloud computing, enabling faster computations and scalability.
Example: Utilizing cloud-based platforms for real-time regression analysis in business analytics. - Interdisciplinary Applications: Expansion into fields like healthcare, finance, and social sciences, adapting regression models to specific domain challenges.
Example: Applying regression analysis in personalized medicine for predicting treatment outcomes based on genetic and clinical data.

Conclusion
Regression analysis remains a cornerstone of predictive modeling, balancing interpretability with predictive power. Ethical considerations, model comparisons, and future trends highlight its dynamic role in data-driven decision-making. Mastering these concepts equips students with critical skills for navigating complex data landscapes responsibly and effectively.
To seize this opportunity, we need a program that empowers the current IT student community with essential fundamentals in data science, providing them with industry-ready skills aligned with their academic pursuits at an affordable cost. A self-paced program with a flexible approach will ensure they become job-ready by the time they graduate. Trizula Mastery in Data Science is the perfect fit for aspiring professionals, equipping them with the necessary fundamentals in contemporary technologies such as data science, and laying the groundwork for advanced fields like AI, ML, NLP, and deep science. Click here to get started!
FAQs:
1. What is the regression analysis of data analysis?
Regression analysis is a statistical technique used to model and analyze the relationship between a dependent variable and one or more independent variables. It is a fundamental tool in data analysis for understanding how changes in the independent variables affect the dependent variable.
2. What is a regression in data science with an example?
In data science, regression is used to predict a continuous or numerical output variable based on one or more input variables. For example, a real estate company may use regression analysis to predict the price of a house based on factors like square footage, number of bedrooms, location, and age of the property.
3. What is regression analysis explain with an example?
Regression analysis is used to understand the relationship between variables and make predictions. For instance, a company may use regression to analyze how advertising spending (independent variable) affects sales (dependent variable). The regression model would provide an equation to estimate sales based on advertising budget.
4. What are the types of regression analysis?
The main types of regression analysis include:
- Linear regression (simple and multiple)
- Logistic regression (binary and multinomial)
- Polynomial regression
- Ridge regression
- Lasso regression
- Elastic Net regression
5. Why is regression analysis used?
- Regression analysis is widely used because it provides several benefits:
- Identifying the strength and direction of relationships between variables
- Making predictions about the dependent variable based on the independent variables
- Determining which variables are most important in a dataset
- Assessing the impact of changing one or more independent variables on the dependent variable
- Validating hypotheses about relationships between variables


